

[ad_1]
Introduction
Data is at the core of Uber. It helps us provide a frictionless app experience and develop the right set of features for users. Critical user-facing functionality like fares, matching, product ranking, ETA/ETD, etc., are ML powered and have data at their heart (Ref: blog).
A user session that groups user activity in a certain time period is critical for all analytics use cases. Many important business and operational metrics are based on sessions (e.g., the percentage of sessions where the user shopped, requested, and completed a trip).
A Session ID is like a glue that ties together important logs across our systems. For example, a user browsing products and requesting a trip on the Uber Rider app generates important analytic logs and events (like product seen, product selected, trip requested, etc.), all of which have the same Session ID.
Motivation
Uber’s app has used multiple definitions of a user analytical session, depending on the department. Specifically, there are two types of sessions: mobile analytical sessions and backend sessions.
The former is generated on the mobile device and captures on-device user impressions and interactions. However, it does not capture backend system signals, which do not have any UI impact. This session definition is commonly used by teams working on mobile devices and user flow analysis.
On the other hand, our internal systems, such as fare calculations and real-time monitoring, rely on backend sessions. These sessions capture limited mobile events, but can capture backend system signals like trip lifecycle and internal systems state. This session definition was useful in debugging and capturing internal system views.
These separate session definitions were created to meet their respective needs. However, they fail to give a 360-degree view of the system. There was no identifier that joined all frontend and backend events in a session. This limited our ability to perform cross-domain analytics and to reuse ML models across different datasets. Due to different session definitions, session-based metrics provided different values for the same line of business.There was no common definition across Uber’s different apps (Uber Rides and Uber Eats) that could help with cross-application analysis. Also, since Backend and Mobile were not in sync on a session definition, we could not run A/B experiments (Ref: blog) on the basis of session_id.
Challenges
We wanted a single session definition that could be governed by marketplace signals and easily tie frontend and backend signals. Developing a fresh session definition and refining our system architecture required a comprehensive approach, which should be able to tackle the below challenges:
- Extensible Session Definition: As the Uber app continues to grow we expand our business to different Lines of Businesses (LoB). We must develop a session definition that flexibly integrates with multiple marketplace signals and seamlessly expands across different LoBs.
- Scalability for Uber-Level Traffic: Uber is one of the most used apps in the world. Our architecture should be scalable enough to handle Uber-scale traffic. Almost all API calls to our app need a Session ID tagging. This new system needed to be highly scalable, as Uber’s platform has almost 131 Million monthly active users and facilitates around 7.6K million trips. (Ref: Annual report 2023 ). On a daily basis, we are seeing ~45 Million unique sessions and on average 72K million mobile events, which need to be attached with a unique Session ID.
- Smooth Migration of Data Lake: Uber extensively uses session_id as the primary key in numerous tables and metrics. Making any alterations to such a fundamental concept could potentially lead to disruptions in data pipelines. Hence, any changes of this nature require a well-thought-out plan and careful execution. We must ensure a seamless transition to the new definition with minimal disruption.
- Fault Tolerance and Resilient Recovery: Session ID is a critical component of our architecture. It is essential to incorporate fail-safe mechanisms into the new Session framework. New architecture must have mechanisms to ensure graceful handling of signal interruptions and unexpected failures, maintain data consistency, and prevent system breakdowns.
Solution: Unified Session
In light of the aforementioned challenges, we devised an innovative strategy for generating and propagating Session IDs, referred to as the “Unified Session.” We selected the moniker “Unified Session” because it links a common Session ID to events and logs originating from mobile and backend systems based on a single session definition. Unified Session architecture is crafted to be extensible, scalable, and resilient to failures, given its extensive adoption across nearly all internal systems.
Extensible Session Definition
Various Lines of Business may exhibit distinct marketplace signals and session start/end indicators. For instance, in the context of our rider business, it’s logical to have an analytical session linked with the initiation and conclusion of trips. Our newly developed Unified Session lifecycle platform must possess the flexibility to seamlessly integrate any novel Line of Business.
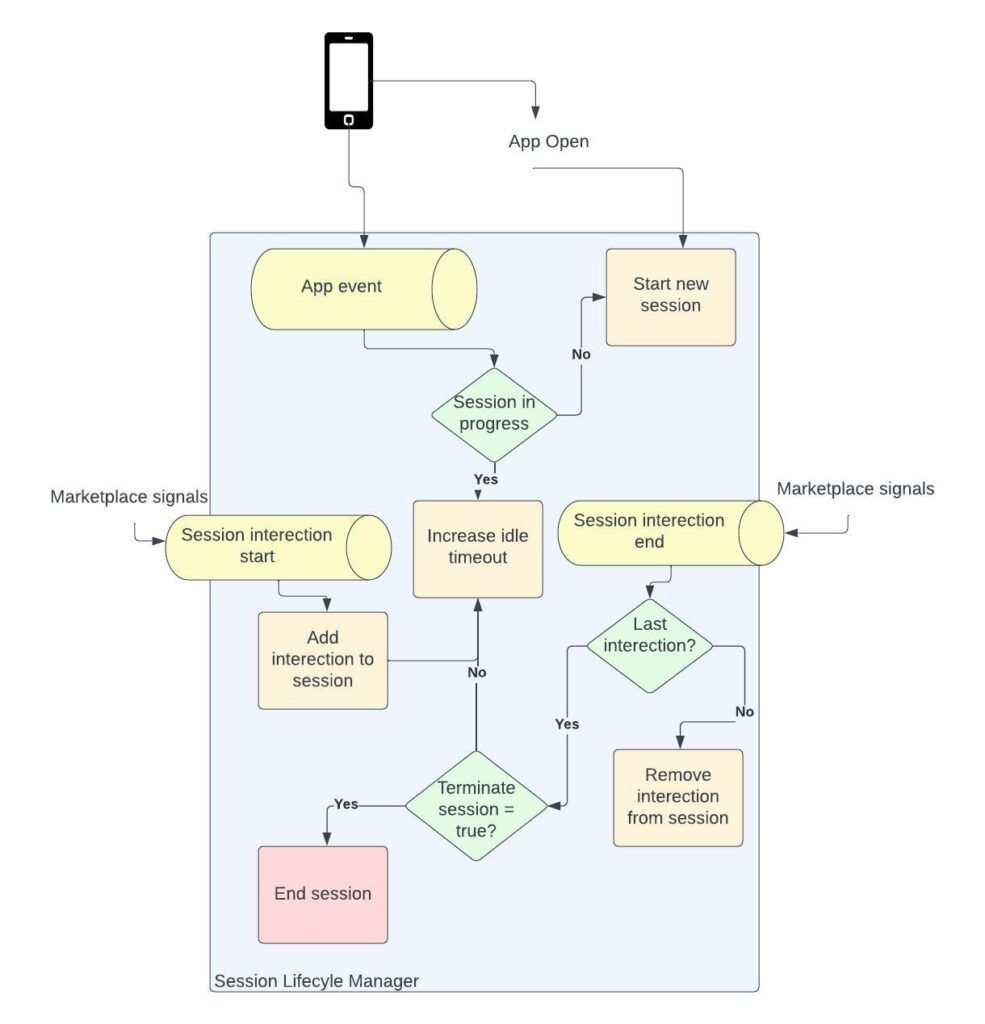
The novel Unified Session delineation commences with the initial API call made from the mobile client. The Unified Session lifecycle is dependent on interaction start and end events. These interaction events encompass various marketplace signals or signals driven by the backend and UI. For instance, in our rider business domain, we capture the commencement of a trip as a trigger for initiating an interaction event. Similarly, an interaction event denoting the conclusion of a trip is emitted upon the trip’s completion. A tally of interactions is maintained for every interaction event within a session. The Unified Session culminates either upon the culmination of all interaction events or following a period of 30 minutes of idle timeout in cases of no interactions (Ref: Figure 1).
Within this framework, the events labeled as Session Interaction Start and Session Interaction End serve as adaptors. They are attuned to diverse marketplace signals and translate them into standardized session interaction indicators. Consequently, these indicators can be effortlessly combined with any app and backend signals to model the session lifecycle. This approach empowers us to expand our session framework to accommodate different lines of business, even when they entail distinctive methods for commencing and concluding interactions.
The overarching Unified Session lifecycle is managed by a backend service, thereby decoupling it from the mobile client code. This simplifies authoring and modifying the session lifecycle using the app and backend signals without any client-side changes. This is especially important because client code is hard to release and debug. This inclusiveness in defining the Unified Session is crucial for enabling cross-application analysis and facilitating the integration of other use cases. Moreover, the platform exposes APIs to fetch current and historical Session IDs for a device, making it simple for any backend service to log session_id.

Scalable System Design
Server-Driven Sessions
To scale for Uber, the backend service for session management needed to handle around 250K QPS. We broke our session management and session read calls into different services. A primary service, the session-manager, is responsible for creating, updating, and reading the sessions in real time, and a supplementary service, session-gateway, which provided quick lookup into existing and past sessions for a given user with minimum latency (~20ms).
Segregation of responsibility: The session-manager service is responsible for consuming session interaction signals. It updates the session state based on this signal. Session interaction signals can be user activity on mobile or marketplace signals. These interaction signals needed to be extensive in order to expand to different LoBs. The start of the session is governed by mobile activity. Whenever mobile makes an API call, our gateway middleware checks for an active session and creates a new one if there is none. This API call also acts as a heartbeat for idle session timeout. Session-manager service updates session status in the persistent cache via a write-through cache
For any call to fetch past and current sessions based on an identifier, a read-only service (session-gateway) was created. This service has a very strict SLA (~20ms) and does a quick lookup into the Redis cache to fetch session information. It falls back to persistent storage in case of cache failure.
Mitigating Redundant Backend Calls: We wanted to avoid repetitive calls to session management service whenever it was possible. As an optimization, we sent out a cookie to the client device when the session started. While this cookie is valid, we read session values from the cookie instead of making a call service. This has reduced around 60% of calls coming from the analytical gateway. Without implementing this optimization in all the gateways, our system would be dealing with four times the amount of traffic
Propagation of Session ID: One of the challenges was how to propagate this information to all services. We wouldn’t be able to fulfill requests from all sub-systems to retrieve the current Session ID. Jaeger™, a distributed tracing platform, helped us propagate information to all microservices in a service chain flow (blog). For other systems that are not in a service path, we can call a session-gateway API to find out the current session for the user.

Mobile Call Flow
All API calls were fetching session information from a backend service. Even after the segregation of responsibilities, it would have difficulty scaling. We needed to add a capacity caching layer to scale down API calls drastically. To do so we started sending session information in the form of a session cookie as a part of the response header of all API calls. Mobile persisted the cookie received in response to the in-memory cache, which was updated whenever a new cookie was received in response. This cookie was propagated back in all request headers. A middleware at the network layer swapped the Session ID with Unified Session ID either with the Session ID present in the cookie or by getting the Session ID from sessionService, based on the validity of the cookie.
The middleware is created for Edge Gateway – Uber’s API Lifecycle Management Platform and Ramen – Uber’s Push Platform and Unified Reporter – Uber’s analytics ingester at client.
The mobile client didn’t unwrap the cookie because it wasn’t able to validate the staleness of the cookie, due to problems like clock skew (difference between client and server time). It also ensured that the logic behind the Session ID remained decoupled from mobile. The expiry time of the cookie was also kept as a very small value to ensure that a stale session is not propagated via the cookie.
Below is the flow of the cookie:

Migration of Data Lake
Once we validated that the backend system could scale to Uber’s traffic, we needed to devise a strategy to test and implement a fundamental alteration that could potentially impact nearly every table. We can either add an extra column for the unified session or overwrite the session column in all tables with a unified session. Below is the comparison of both the approaches:
| New column for unified session | Overwrite Existing column |
| Need to point queries to new column | No change in current queries |
| Code change required for downstream tables | No need for any change as Unified Session ID will flow seamlessly in place of current Session ID |
| Tables where old Session ID and Unified Session ID have one-to-many mapping will not be able to take this approach | Tables where Session ID and unified session ID have one-to-many mapping will have more rows |
| Staggered rollout is supported by creating parallel tables | No support for staggered rollout as joining between tables on Session ID might break |
| Rollback is relatively easy | Can’t do rollback, as the original Session ID is overwritten |

To overcome this shortcoming of each approach, we broke migration into 2 phases: The Validation Phase and the Migration Phase
Validation Phase
We created parallel tables for some of the crucial tier-1 tables. These tables replaced old session information with a unified session. We ran test cases that we have on the current tables and compared the metrics of these tables with the current tables. In addition to that, we performed detailed validation with regards to session behavior on top of these tables and published behavioral differences documents to educate organizations about these changes.
Migration Phase

Once these parallel tables were certified, we started replacing legacy Session IDs with Unified Session IDs. The challenge here was where should we replace the legacy Session ID. If we perform the Session ID swap at tier-1 tables, it has to be orchestrated carefully. Otherwise, the Session ID joins with the downstream table and the migrated table will break. This needed all tables to start consuming the Unified Session ID at the same time. This can be extremely difficult, and rollback can be extremely painful.
We decided to swap the old Session ID with a Unified Session ID at the gateway layer. We already had a middleware to enrich all API calls with session information in the header. We enhanced this middleware to swap Session ID with the Unified Session ID. It allowed a natural propagation of the Unified Session ID throughout the architecture. Services need not add any more logic to consume them and can be seamlessly moved to the new definition. Also, at the gateway level, we were able to control rollout with a feature flag. It allowed us to do a staggered rollout and compare metrics at each major milestone.
Resilient Recovery
Any failure or downtime in the session-manager and session-gateway services can impact our ability to generate new Unified Session IDs and stamp events with Unified Session IDs. This could have a negative impact on our forecasting models and analytics. To address this rare scenario, we have developed a contingency platform designed to infer Unified Session IDs for any event. This platform consists of two components: Session Recreation and Session Patching.
The Session Recreation service retrieves all signals and interaction events from the logs in order to recreate the session lifecycle. It generates an Apache Hive™ table with Unified Session IDs and metadata.
The Session Patching component is a platformized batch pipeline that takes a table, event column, event time, and rider ID as inputs. It then performs a conditional join based on the session’s start time, end time, event time, and rider ID for the provided table. This process aims to infer the Unified Session ID for the event and overwrites the Session ID column with the inferred Unified Session ID. This updated Session ID can be propagated to all downstream tables by re-running downstream pipelines.
Conclusion
By implementing a unified session definition, we established a singular perspective for all analytical metrics. This has helped us in removing redundant logging libraries. This unified session acted as a linking factor across various domains, enhancing data reusability between multiple sessions. Thanks to its extensible and backend-driven nature, the session definition seamlessly incorporates signals from diverse lines of business, such as micro-mobility, rentals, public transit, and taxis. Consequently, logging of sessions across domains has surged, enabled by the platform’s ability to retrieve session information.
The existing Unified Session architecture boasts an adaptable design and the versatility to monitor multiple streams. It holds the potential for expansion across various marketplace signals. This, in turn, will facilitate attribution use cases across Uber’s range of applications.
Apache®, Apache Hudi, Hudi, the triangle logo, Apache Spark, Spark, the star logo, Apache Kafka, Apache HBase, and Apache Parquet are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks.
[ad_2]
Source link



