

[ad_1]
Background
As Uber continues to grow, the sheer volume of data we handle and the associated demands for data access have multiplied. This rapid expansion in data size has given rise to escalating costs in terms of storage and compute resources. Consequently, we have encountered various challenges such as increased hardware requirements, heightened resource consumption, and potential performance issues like out-of-memory errors and prolonged garbage collection pauses.
To address these challenges and optimize storage cost efficiency, we have embarked on several initiatives. These include the implementation of Time to Live (TTL) policies for aging partitions, the adoption of tiered storage strategies to transition data from hot/warm to cold storage tiers, and the optimization of data size at the file format level. In this blog, our primary focus will be on the latter aspect—reducing data size within the Apache Parquet™ file format by selectively deleting unused large size columns.
When tables are created, table owners enjoy the flexibility of defining their desired columns without strict governance. However, it is common for certain columns to remain unused, resulting in the unnecessary occupation of significant storage space. Through careful analysis, we have uncovered substantial data savings on a large scale simply by removing unused columns from specific tables.
Introduction of Apache Parquet™ Data Structure
Since Apache Parquet™ is our main data lake storage file format, the column deletion is implemented in Parquet™ file format.
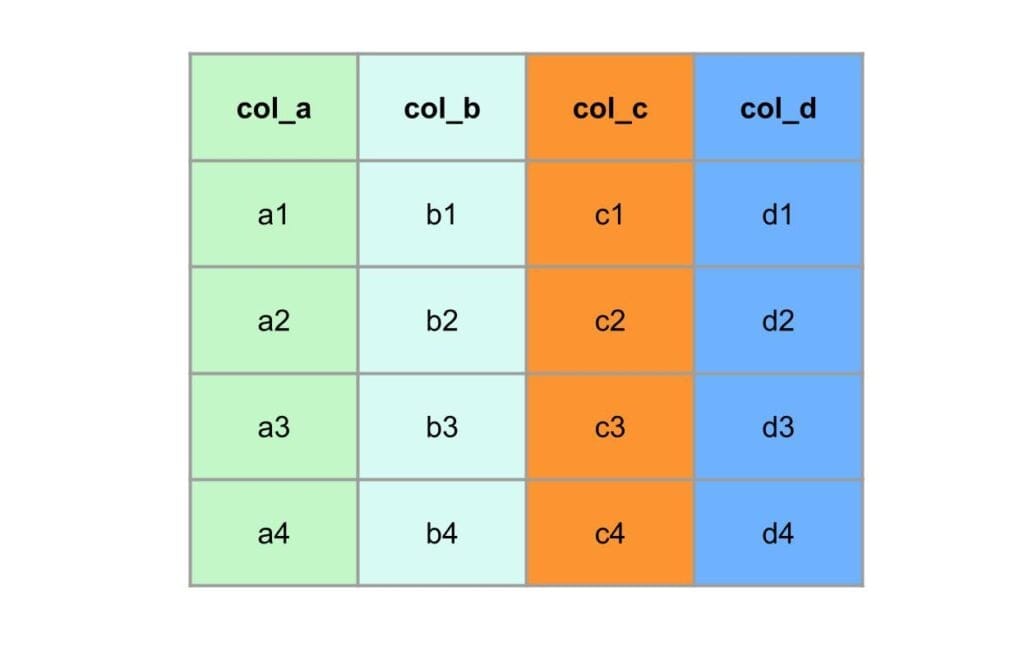
Apache Parquet™ is a columnar file format, meaning that all data belonging to the same column is stored together in a column chunk. The diagram below illustrates the comparison between row-oriented storage and column-oriented storage. In this table, there are 4 columns, and each column contains 4 fields.

In the row-oriented storage, the data is stored row by row.

In the column-oriented storage, the data is stored column by column.

Inside Apache Parquet™, the data is partitioned into multiple row groups. Each row group contains one or more column chunks, which correspond to a column in the dataset. The data within each column chunk is stored in the form of pages. A block consists of pages and represents the smallest unit that needs to be read entirely to access a single record. Within a page, except for the dictionary page encoding, each field is appended with its value, repetitive level, and definition level.
The diagram below illustrates the structure of a Parquet™ file. For further details, please refer to the official Parquet™ file format documentation.
Possible Solution
To remove selected columns from existing data, one common approach is to use Spark™ for reading the data, eliminating the unnecessary columns in memory, and writing back the modified dataset. However, let’s delve into the process of how a Parquet™ file is changed, assuming there is no reshuffling of data across files, as reshuffling can consume additional resources due to its expense.
The steps involved in modifying a Parquet™ file include decryption, decompression, decoding, and record disassembly during the reading phase. These operations are necessary to access and process the data within the file. Similarly, during the writing phase, record assembly, encoding, compression, and encryption steps are performed to prepare the data for storage. It’s important to note that these steps are computationally expensive and contribute significantly to the time required for reading and writing Parquet™ files. The resource-intensive nature of these operations can impact overall performance and efficiency, prompting the need for a more efficient solution to remove columns without relying heavily on these steps.

In order to optimize the process, it is crucial to find a method that minimizes the reliance on the costly steps mentioned above. By doing so, we can reduce the computational overhead and improve the overall performance of column removal in Parquet™ files. This optimization becomes even more important when dealing with large datasets where the impact of these operations is magnified. Finding a streamlined approach to selectively remove columns without resorting to extensive data processing steps can significantly enhance the efficiency and speed of the process.
Selective Column Reduction Solution
Since Parquet™ is a columnar file format and the data in the same column is stored together, instead of performing the expensive steps above, we can just copy the original data for a given column and send it back to disk and bypass those steps. For the columns that need to be removed, we can just skip and jump to the next column that doesn’t need to be reduced. In the end, the offset will be changed and we can update metadata to reflect that. In this process, there would be no data shuffling needed at all. The data in the same file will be output to a new file that contains all the data except for the ones in the column to be removed.

The “Copy & Skip” process can be described as below. Assume columns col_b and col_c are to be removed. The hybrid reader and writer started with copying col_a and there are no expensive steps like encryption, compression, encoding, etc. Instead, it is just literally byte buffer copy. When starting col_b, we see col_b is the column to be eliminated, so we move on to the next column and find col_c also needs to be removed, then we move on to col_d and start copying. In the end, the new file contains two columns’ data (col_a and col_d) and excludes columns (col_b and col_c).
From the above Copy & Skip process, we can see it is vastly improved by bypassing the expensive steps. It is worth noting that there will be no reshuffling data needed, which could be another huge improvement because reshuffling is also very expensive.

Benchmarking
We have benchmarking tests with a local host for reading files that have sizes from 1G, 100M, and 1M in bytes. As a comparison, we use Apache Spark™ as the baseline for the test. From the chart below, we can see the Selective Column Pruner is ~27x faster when the file is at ~1G and ~9x faster when the file size is 1M.

Parallelization of Execution
So far we have discussed the improvement on a single file which builds up the foundation for reducing columns in a dataset. But in reality, a dataset is organized as tables and sometimes is further divided into partitions that usually have a list of files. We need an execution engine to parallelize the execution of the Selective Column Pruner. Apache Spark™ is the distributed execution engine that is widely used. It is a little confusing that in the above section, we use Spark™ for executing the reduction directly. Here, we just use the Spark™ Core to parallelize the execution instead of relying on its Data Source to operate on data directly.
The code samples are as below:

During execution, generally we deal with the dataset as the unit. For each dataset, we list all the partitions if it is a partitioned table, and inside the partition we list all the files under it, and then assign tasks to each file to execute the column reduction using the Selective Column Pruner we discussed above. The dataset snapshot can be described as below:

Conclusion
In summary, our selective column reduction approach within the Parquet™ file format has proved to be a highly efficient solution for optimizing data storage. By eliminating unused columns, we can reduce storage costs, minimize resource consumption, and enhance overall system performance. As Uber continues to evolve, we remain dedicated to exploring innovative ways to improve data management practices and maximize the value of our data assets while minimizing associated infrastructure costs.
Apache®, Apache Parquet™, Parquet™, Apache Spark™, and Spark™ are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries.
Cover Image Attribution: Image by Ian and under CC BY 2.0.
[ad_2]
Source link

