

[ad_1]
Background
SPIFFE
Historically, many organizations have adopted a perimeter-based security model that focuses on bolstering the edge of a private network with security controls like firewalls and VPNs. This approach to network security establishes implicit trust between all remote processes within a company’s private network. In this model, there is a fundamental assumption that traffic within the private network originates from authentic sources, and unprivileged actors have no way to access the network.
While this model is conceptually simple, numerous high-profile data breaches in the past few years have brought to light the glaring insufficiencies of assuming broad trust within a private network. Many companies have responded by evolving their security architectures around a concept called Zero Trust networking, which inverts the paradigm that private networks are inherently trusted by relying on a threat model where there is always assumed to be a threat actor present on the private network. The Zero Trust security model addresses the limitations of perimeter-based approaches by defining the need for explicit authentication controls enforced in each service and removing trust in network-related identifiers such as IP addresses.
Along with the industry shift towards Zero Trust security, web service providers and internal application developers have rapidly adopted distributed system architectures with decomposition of functionality into microservices, portability using containers, orchestration of containers with Kubernetes, and migration of workloads to the cloud. Many application developers can no longer identify a service purely based on where the service is running (e.g., IP address, subnet), since workloads have become more ephemeral in nature and may run in a variety of private or public clouds on shared infrastructure. Application developers also often have little to no control over where their workloads run, as companies have increasingly invested in centralized deployment platforms that abstract away infrastructure management to dedicated teams. Furthermore, since cloud provider platform identities may not be interoperable, an organization distributed across multiple cloud provider platforms may find native solutions insufficient.
Given all the recent evolutions in security and software architecture, a common challenge that application developers now face is how their applications can authenticate themselves with other services that may be running on different virtual or physical hosts. At Uber, with our multi-cloud infrastructure and microservices architecture, we face these challenges at a large scale, with 4,500 services running on hundreds of thousands of hosts across four clouds.
In an effort to address this problem, the open source community has united on a project called SPIFFE (Secure Production Identity Framework For Everyone). SPIFFE is a set of open-source specifications that provides a framework for implementing Zero Trust security by defining primitives for:
- How to canonically represent the identity of a workload (SPIFFE ID)
- How a workload’s identity can be encapsulated into a cryptographically-verifiable document, known as an SVID (Secure Verifiable Identity Document), such as an X.509 certificate or JWT (JSON Web Token)
- How workloads can obtain their own SVIDs (Workload Endpoint and Workload API)
- How public signing key material can be represented and exchanged so that workloads can verify SVIDs and perform strong authentication (Trust Domain and Bundle, Federation)
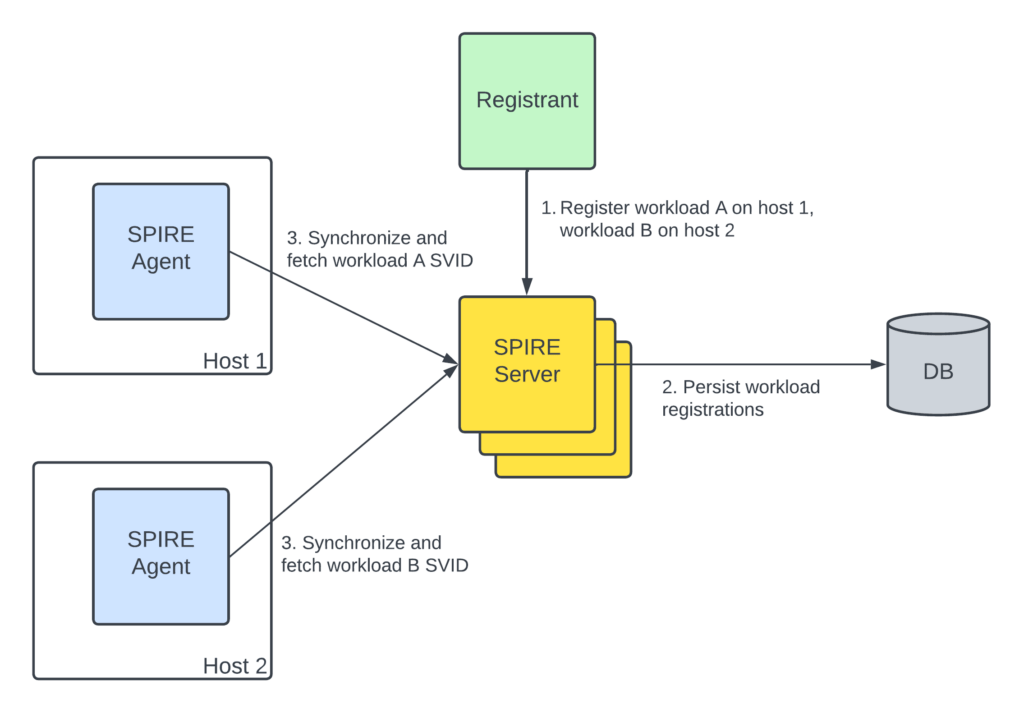
SPIRE (SPIFFE Runtime Environment) is an open-source implementation of the SPIFFE specifications. It is designed to flexibly support heterogeneous deployments of workloads across clouds and orchestration platforms. A key feature of SPIRE is its ability to automatically rotate X.509 certificates and push rotated certificates to workloads over long-lived streams, enabling availability of workload identity in large-scale deployments with minimal operational overhead for development teams.

SPIRE consists of two components: a server and an agent. The server is responsible for managing a set of registered workloads and signing SVIDs. The agent frequently synchronizes with the server to fetch the set of SVIDs that it is authorized to serve to workloads. Registrant services integrate with the SPIRE control plane to define workload identities with a few key properties:
- The SPIFFE ID of the workload
- How to identify the workload based on process runtime attributes, such as Kubernetes pod information, Unix user ID, and container labels
- Which hosts the identity should be available on

SPIRE Agent relies on this registration information to discover how to associate workloads to a particular identity in a process called workload attestation. The agent hosts the SPIFFE Workload API, an unauthenticated API used by workloads to fetch their identity. The Workload API discovers caller process metadata through configured trusted authorities such as the kubelet, Linux kernel, and container runtimes. Workload attestor plugins map the discovered metadata to “selectors” which SPIRE Agent then compares against the registrations it learned about from SPIRE Server, and provides any matching SVIDs to the caller.
SPIRE’s Role in Uber Infrastructure
We use SPIRE at Uber to provide identity to workloads running in multiple clouds (GCP, OCI, AWS, on-premise) for a variety of jobs, including stateless services, stateful storage, batch and streaming jobs, CI jobs, workflow executions, infrastructure services, and more. We have worked with the open source community since the early stages of the project in mid-2018 to address production readiness and scalability concerns.
In order to understand the motivations for the design and architecture decisions of SPIFFE/SPIRE at Uber, it’s helpful to understand what Uber’s production environment actually looks like. Every machine at Uber runs a single, immutable, “golden” OS image with the exact same set of base software. Any production workloads that wish to run on a host must be containerized.

Uber runs servers both in the cloud and leased data centers. In addition, we run across several different cloud providers. Therefore, any solutions we build must work equally well in all environments and all workloads must be able to interoperate across datacenters and providers. Notably, this means provider-specific identity solutions are a non-starter for our identity infrastructure.
Lastly, because we want strong identity at the lowest levels of our infrastructure, our identity control-plane must take on the least amount of dependencies possible. A guiding principle of our Crane infrastructure is that we should be able to provision new zones in a fully automated fashion. This means that identity solutions must be architected in such a way that prevents circular dependencies for low-level systems like DNS, which still require some form of identity.
Adoption Strategy
At Uber we have:
- A diverse set of workload scheduling platforms, each suited for a particular need across compute, storage, and data processing
- Thousands of microservices and jobs in varying states of the software lifecycle and varying scopes of business impact, from core infrastructure and product hot paths to proofs of concept and experiments
- Decentralized, organic growth in the number of production services and jobs, driven by a technical and cultural value of team autonomy to define new services and jobs
Workloads must be able to scalably obtain their identity and leverage it for authentication in a way that is congruent with our large, dense microservice call graph. We must allow our workload developers the freedom to focus on their core business logic with the assurance that their data is protected and that their processes will have reliable, authenticated access.
The diversity of workloads led to three major functional needs:
- How can we reduce workload developer burden? As much as possible, developers should not need to worry about the details of their security integrations.
- How can we ensure SPIRE will uniquely identify workloads from each other in a meaningful way? An inconsistent or overlapping identifier setup may lead to inaccuracy or unavailability of authentication, and increase security maintenance burden.
- How can we know which identities are needed where in the fleet at any given time, and make those identities available? Globally registering all possible identities in-memory of every host is a security and scalability non-starter: the compromise of one host should not mean the compromise of all workload identity, and our fleetwide agent should have as little overhead as possible to be cost efficient.
Workload Integration
To abstract away security code from developers, we developed an Auth library in Uber’s core backend languages, Go and Java. With an import declaration and minimal one-time service configuration, the library will:
- Subscribe to spire-agent for an SVID, and SVID renewals
- Use the SVID to inject identity into outbound requests with RPC middleware, which can take the form of tokens and/or TLS
- Authenticate inbound signed tokens with RPC middleware, and perform further authorization as determined by the workload’s access policy
With the Auth library handling these above points, the service developers can focus on their business logic.

Developing a library was chosen over other solutions like binary distribution in order to take advantage of our various other standardization efforts:
- Go and Java monorepos and CI-CD architecture. When updates are made to libraries we can receive immediate feedback from multiple levels of testing to ensure that no consumers will be broken. Additionally when updates are merged we can know that most production workloads will be deployed with the updates automatically over a brief period.
- Unification on a common set of RPC frameworks, allowing reusable middleware.
To further improve service developer experience, we are working towards push-button onboarding commit generation as well as authorization policy recommendations based on real traffic.
Workload Identification
SPIRE comes with multiple built-in options for performing workload attestation. We primarily use container-based attestation, since our workloads are containerized in production. Trusting workload launchers (which themselves are attested with SPIRE) to apply consistent container labeling, we can uniquely identify service containers from each other by service name, environment, and the launching platform.
Challenges
Managing SPIRE Agent Infrastructure
Managing SPIRE Agent on Uber’s fleet of over ¼ million nodes across a number of geographic zones is challenging in a number of ways. We’ll highlight a few of the more difficult ones here.
Deployment
As mentioned above, we leverage an immutable, “golden” OS image to handle agent deployments for all types of operating environments. The golden OS image is rolled out incrementally across all zones on a regular schedule so we need to coordinate and align with other teams when we upgrade SPIRE Agent. Inclusion of the SPIRE Agent binary in the golden OS image doesn’t solve all of our requirements by itself.
As a fleetwide host agent, we need to minimize the system resources SPIRE Agent can consume. We run the SPIRE Agent as a Unix process with cgroup restrictions on both CPU and memory. We balance the host resource footprint vs. health of the SPIRE Agent by tuning these restrictions.
Due to the heterogeneity of our fleet, we need to customize our SPIRE Agent configurations based on the type of environment in which they are operating. To accomplish this, we developed a configuration-generator binary that we also place in the golden OS image. This process gathers the necessary metadata to write the SPIRE Agent configuration on a given node. We run it as part of starting SPIRE Agent so it has the capability to update SPIRE Agent configuration on every restart of SPIRE Agent.
Observability and Mitigation
We need observability that detects an individual failure on any host in the fleet without a high rate of noisy inactionable detections causing undue burden for our on-call rotation to mitigate. Fortunately, we have teams dedicated to host and infrastructure management that maintain a host health monitoring system with an extensible observability and alerting framework. We were able to integrate with those systems at Uber to meet this challenge. However, there are differences in the life cycle of hosts running stateless compute workloads and hosts running stateful workloads with large amounts of data persisted on local storage. We had to solve both cases with automated mitigation as the goal. We achieved fully automated mitigation for stateless hosts and partially automated mitigation for stateful hosts, but it has been a long journey, as described below.
Architecture

Health Trends
We leveraged a fleet-wide host management agent to connect to the SPIRE Agent workload API over the local Unix domain socket to fetch an SVID as a health check every 10 seconds, emitting metrics. We found that simple counts of success, failure, and error led to false positives, triggering noisy alerts; for instance, high load average and hosts entering or leaving production state tended to cause false alarms. To address this, we added a health check trend gauge, which gets incremented on failure up to a max value and decremented on success. We set a threshold roughly in the middle between zero and max value. We found that this mostly avoided detecting agents degraded by high load average on the host, which would recover on their own when the load spike ended. That gauge was the key to taking the next step toward automatic mitigation. By smoothing out intermittent, spiky failures, we finally had a reliable signal still within a reasonable time to detect unhealthy SPIRE agents.
Bad Hosts
Our host management control plane has a framework for detecting unhealthy or faulty hosts and taking an action to mitigate based on the type of failure detected. We plugged into this framework using the SPIRE Agent health trend gauge to determine whether a host’s SPIRE Agent was healthy or not. We ran this check in preview mode for some time to build confidence and tune the mitigation threshold. Once we were ready, we enabled automatic reboots for hosts running stateless workloads and marked hosts running stateful workloads as bad so they are hooked into a mitigation pipeline for stateful hosts.
Total Visibility
After turning the corner to automatic mitigation, we still want visibility in a layered defense against catastrophe. We continue to graph the SPIRE Agent health trend gauge for every host in the fleet on our dashboard. We have additional alerting and graphing of metrics from the SPIRE Agent and its system resource usage that are not part of this automated mitigation system.
Managing Workload Registrations
We chose a node-alias-to-logical-host-group registration strategy while initially integrating SPIRE into our infrastructure to minimize identity propagation delay and maximize attestable workloads. The workloads we’re attesting are nearly all containers, but do include some Unix processes that support the infrastructure to run the containerized workloads. Specific hostnames can sometimes be reassigned to different host groups with different authorized workloads or reused after removal from the fleet. At least one Unix-attested workload needs to run on all hosts in the fleet.
The node aliasing essentially works by adding a selector based on hostname to the node entries when SPIRE Agents attest, registering host group SPIFFE IDs mapped with those selectors, and using the host group SPIFFE IDs as the parent IDs for the workload registrations that should run on a given host group. A minimal host group node alias registration looks something like this:

A minimal registration for a workload authorized to run on that host group looks something like this:

In this way, workloads stay associated with specific host groups, but specific hosts can be moved in or out of any given host group which alters its set of authorized workload entries. We use a similar scheme with a custom static selector added to all node entries and mapped to an “all-hosts” node alias entry.
SPIRE Bridge(s) Architecture

Uber infrastructure includes a single source of truth for node metadata, on which we rely for our node aliasing to host groups. We settled on a “SPIRE bridge” for our registrant design as the simplest way to handle a variety of schedulers while synchronizing against the monolithic node metadata. Some schedulers can notify our bridge services when they schedule workloads, but the bridge must poll others. For schedulers that do push notifications, we also perform a lower-frequency poll to further ensure registration integrity by reconciling against current registration state to correct for any missed or duplicate events.
Reliability/Scale
As we ramped up our adoption of SPIRE at Uber, we ran into several scaling and reliability challenges. We have contributed back multiple improvements to upstream SPIFFE and SPIRE to better support high availability of SPIRE and simplify onboarding for new users.
SPIRE Server Read Replica
One such improvement we contributed in the earlier days of the project was to enable the usage of database read replicas for read-intensive operations. This helped us scale read operations by taking advantage of the MySQL read replicas in our database clusters. Prior to that, the SPIRE database plugin took only a single connection which handled all the database node operations and hit the primary MySQL node. We enabled support for additional database connections that could optionally be used for read-intensive operations, thus allowing us to distribute the heavy read load horizontally across multiple read replica nodes and balancing the security-sensitive read operations to primary nodes.
The below image demonstrates a sample test with a MySQL cluster of 3 DB servers – one primary write instance (yellow) and 2 read replicas (green, blue). By moving read-heavy operations like ListRegistrationEntries and GetNodeSelectors to the read-only replica, we were able to distribute the read load across multiple read replicas and use the primary node for write operations.

SPIRE Agent LRU Cache
We organize our production hosts into groups dedicated by use case (e.g., compute cluster, infrastructure control plane) and store the host-to-group associations in a host catalog system. In many cases, we register workload identities to be available for all hosts in a host group. SPIRE Agent caches each SVID it is supposed to manage. Therefore, each host of the group needs to cache all those SVIDs. This setup can quickly scale up and will require each host to cache thousands of SVIDs. SPIRE Agent runs as a fleetwide host agent, so we must minimize required resource overhead in production. Anticipating undesirably high memory usage in the future, we implemented an LRU cache inside SPIRE Agent to store SVIDs. This ensures that we can keep providing workload identities across a group of hosts while consuming a predictable amount of memory on the host. With this improvement, we are able to register around 2.5 times more workloads for a host group. It also translated into fewer signing requests to SPIRE server, thereby reducing CPU usage by 40%.

Closing
Establishing Zero Trust architecture within Uber production via SPIRE has been an incredible, ongoing journey. It has furthered our continual push to Do The Right Thing with the data our customers and partners entrust us with, so that tightly-scoped accesses may be enforced against the fleet and are backed by strong cryptographic verifications. Critically, SPIRE enables us to do this with minimal assumptions about our ever-evolving data center and platform architecture.
We look forward to posting more on in-depth topics around SPIRE at Uber in the future, such as our Secrets program and Service Mesh.
If you have more questions about SPIFFE or SPIRE, join the community at slack.spiffe.io. Our team is also active there, and happy to continue conversations on advancing security across global operations.
[ad_2]
Source link


