

[ad_1]
Introduction
If you were to ask a veteran SOC (Security Operations Center) analyst about Network IDS (Intrusion Detection Systems) or IPS (Intrusion Prevention Systems), the response would probably contain phrases such as “too many alerts,” and “false positives.” At Uber, we face these same challenges of volume, accuracy, and manageability. Multiple times a day, more than 90,000 IDS rules are parsed, analyzed, updated, filtered, and deployed to our network sensors. Aristotle v2 was created to enable us to automate this process, apply induction-based intelligence extraction, and enhance rule metadata to reduce false positives and help ensure that appropriate IDS alerts receive proper attention.
Overview
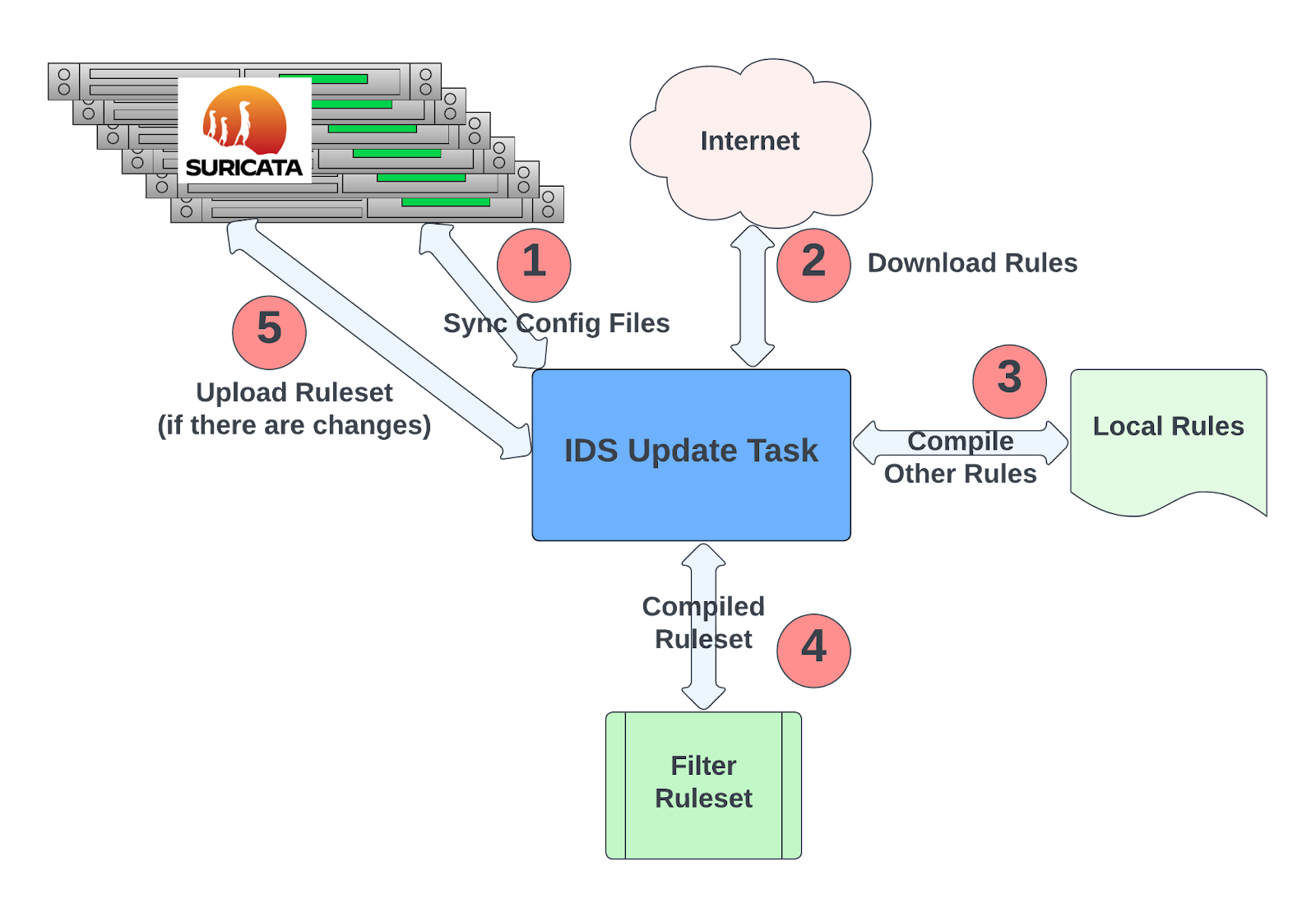
The IDS ruleset update process at Uber involves multiple steps, as shown in Figure 1. Collating and distributing rules is straightforward and common to all Suricata™ deployments. Deciding which rules to include and how they should be modified is what happens in step 4, “Filter Rulesets,” and will be the focus of this blog.
Background
IDS alerts are generated by IDS engines operating on logic governed by rules (or “rulesets”). At a basic level, IDS rules can be thought of as advanced pattern matching against network traffic and connection state. The most popular open source Network IDS engines are Suricata and Snort™. This article focuses on Suricata, but the concepts and practices can also apply to Snort.
IDS Rule Selection Approaches
Choosing which rules to apply to particular sensors can have a significant impact on false positive rates, undesired IDS alerts, and engine performance. For example, sensors protecting a pool of Linux® web servers don’t need to be running rules designed to detect attacks that target Windows® file sharing.
Rule Classification
Historically, ruleset consumers have used two big “knobs” when it comes to choosing which rules to enable or disable. The first is the “classtype,” a native rule keyword with a finite set of options, which are defined by the ruleset provider and attempts to categorize the rule. Usually, no more than a few dozen classtype categories are defined, and common values include “trojan-activity,” “attempted-dos,” and “bad-unknown.” The second knob is the filename of the file that the rule is placed in by the ruleset provider, who will often segregate rules into different files with names like “sql.rules,” “scan.rules,” and “trojan.rules.”
A major problem with these “knobs” is that they don’t allow for a one-to-many mapping. Each only supports a single value for a single rule. This lack of flexibility can be restrictive. For example, should a rule that detects recently seen exploit kit activity go into the “current-events.rules,” “exploit.rules,” or “web-client.rules” file (just to name a few options)? A similar challenge exists for the “classtype” field, where the activity being detected could legitimately be classified into multiple categories. These finite, blunt rule classification mechanisms are too broad to support the ruleset fine tuning flexibility needed for modern deployments.
Manual Review
In order to optimize rulesets for particular environments, they must be tuned. Often this results in a non-trivial, ongoing, and manual effort. In fact, some companies have a daily task of manually inspecting each new rule, deciding if it should be included, and then tuning it as necessary. However, this quickly becomes onerous and manifestly doesn’t scale, especially if existing rules have to undergo regular re-tuning as well.
Metadata
There exists a “metadata” keyword, supported by IDS engines like Suricata and Snort, that allows for arbitrary key-value pairs to be embedded into each rule. This can be extremely helpful in deciding which rules to enable because rules can be filtered based on the content of the metadata. Suricata will also include the metadata in the IDS alert, which can be used for more informed post-processing, decision making, and correlation.
Metadata key-value pairs provide distinct advantages over traditional rule categorization, including:
- One-to-many mapping: For example, the “protocols” metadata key can have values “http” and “tcp”
- Arbitrary key names and values: Classification doesn’t have to be limited to pre-defined, finite options
A BETTER Way
The BETTER (Better Enhanced Teleological and Taxonomic Embedded Rules) schema for key-value based IDS rule metadata was proposed in 2019. It recognized the need for one-to-many metadata mappings, and attempted to bring some structure and standardization to commonly used metadata keys and (in some cases) values. One vendor—Secureworks®—fully implemented BETTER in its Suricata ruleset offering, while other vendors such as Proofpoint ET Pro®, have rulesets with partial compatibility. BETTER never received widespread industry adoption, but its major concepts persist, and the use of metadata for ruleset filtering is still a solid strategy.
Many ruleset providers do populate metadata, but almost all of them do so in a way that severely limits the effectiveness of using metadata as a means of rule filtering. Specifically, the rulesets have one or more of the following shortcomings:
- Missing metadata: Either applicable metadata key-value pairs are not used in the ruleset, or metadata key-value pairs are applied selectively instead of universally. Filtering rulesets based on metadata is most useful if all applicable metadata are applied to all applicable rules, and utility falls off sharply when this is not the case. For example, setting the metadata “attack-target http-server” on 20 rules in the ruleset when there are 400 more rules that could be classified the same way, makes filtering based on that key-value pair of limited value.
- Inconsistent value formatting: For example, “cve” key values may appear as “cve_2023_1234,” “cve_2023_1234_cve_2023_2468,” “2023_1234,” “2023-1234,” etc. Without a normalized nomenclature, accurate filtering becomes challenging.
- Poor value formatting: This includes things such as not using standard datetime formats like ISO 8601 when specifying time/date strings.
Aristotle v1
In 2019, Secureworks released Aristotle (v1), an open source Python tool that allowed users to “filter” (enable or disable) rules based on metadata key-value pairs. By using a concrete boolean algebra, “filter strings” can be defined to control rule selection. This can be quite powerful, but the usefulness of Aristotle v1 is limited by the richness (or rather, lack thereof) of the metadata in the provided rules, something controlled by ruleset vendors and onerous to maintain manually. Since most ruleset vendors do not provide comprehensive metadata and/or do not have metadata with the precision and consistency needed for accurate programmatic filtering, something more than Aristotle v1 is needed.
Metadata and Beyond
Aristotle v2
Uber recently contributed significant improvements to Aristotle, resulting in Aristotle v2. These updates added support for metadata normalization, enhancement, and manipulation. Figure 2 shows the different components of Aristotle v2, which will be discussed in more detail.
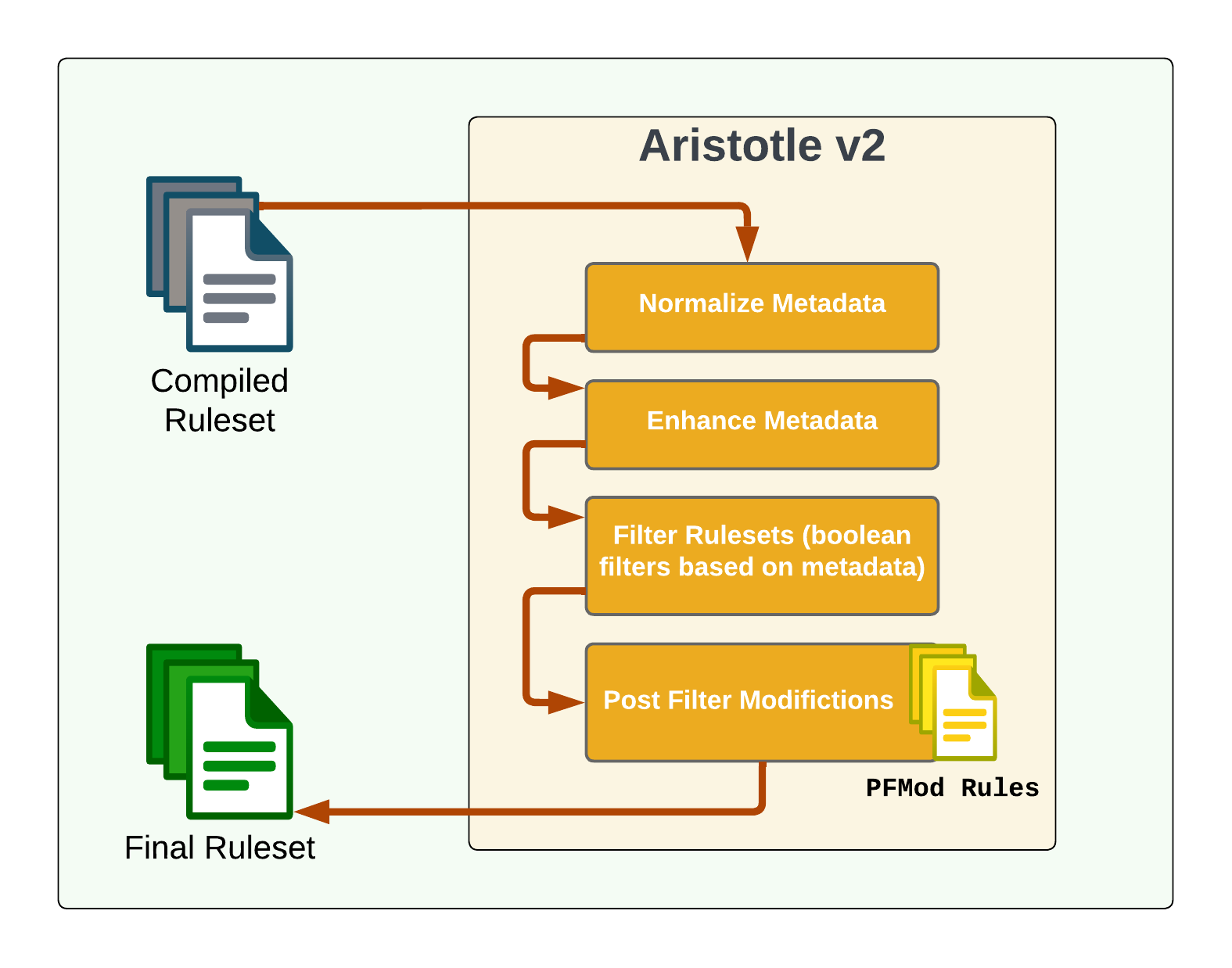
Filtering
Aristotle v1—which is basically the “Filter Rulesets” step—did a good job of supporting boolean filtering on metadata, and even included the ability to specify numerical relationships for certain keys (e.g., “created_at > 2023-01-01”). To the list of keys that support such comparisons, Aristotle v2 added risk_score (more on that key later).
Additionally, the ability to do regular expression based filtering was introduced in Aristotle v2. While this does impact filtering performance because it adds non-literal elements to the boolean expression, it does provide powerful and often needed capability. Specifically, regular expression matches can be applied to the entire rule with the “rule_regex” keyword, or scoped to just the “msg” field with the “msg_regex” keyword.
Normalization
To address the filtering challenges that come from a lack of consistent metadata value format, Aristotle v2 supports the normalization of certain metadata key values. Specifically, the following normalizations are supported:
- CVE key value(s) normalized to format YYYY-<num>. If multiple CVEs are represented in the value and strung together with a “_” (e.g., “cve_2021_27561_cve_2021_27562” [sic]), then all identified CVEs will be normalized and included.
- Values from the non-BETTER schema keys mitre_technique_id and mitre_tactic_id will be put into the standards compliant mitre_attack key.
- Date key values—determined by any key names that end with “_at” or “-at”, e.g., created_at—will be attempted to be normalized to ISO 8601 format YYYY-MM-DD.
Enhancement
While normalizing metadata is necessary and useful, it can’t address the issue of missing metadata. However, a rule is more than its metadata, so we asked the question, “can we identify, deduce, induce, or otherwise infer particulars from the rule’s ontology, and augment the rule metadata with that information?” This led to creating the ability of Aristotle v2 to analyze the ontology of each rule and add/update the metadata with the following enhancements:
- flow key with values normalized to be either “to_server” or “to_client”
- protocols key and applicable values
- cve key and applicable values. The value(s) are based on data extracted from the raw rule, e.g., “msg” field, “reference” keyword, etc.
- mitre_attack key and applicable values. The value(s) are based on data extracted from the rule’s “reference” keyword
- hostile key and applicable values (“dest_ip” or “src_ip”)—the values are the inverse of values taken from the “target” keyword
- classtype key and applicable values
- filename key and applicable values—the value will be the filename the rule came from, if the rule was loaded from a file
- originally_disabled key and boolean value get added on each rule internally, to be used for filtering
- detection_direction key (see below)
Detection Direction
While network IDS rules can be unidirectional, the overwhelming majority of them are written to target just one side of the client-server communication. Additionally, rules are typically scoped by specifying IP address groups for the source and destination. IP address groups are user-defined but almost always include the variables “HOME_NET” and “EXTERNAL_NET.” The idea is that HOME_NET is the group of IP addresses owned by the user or company, and intended to be protected; and EXTERNAL_NET is the group of IPs “outside” the user’s network, typically the general Internet. EXTERNAL_NET is often (but not necessarily) defined as everything that isn’t specified in HOME_NET.
The detection_direction metadata key attempts to normalize the directionality of traffic on which the rule detects. To do this, the source and destination sections of the rule are processed and reduced down to “$HOME_NET”, “$EXTERNAL_NET”, “any”, or “UNDETERMINED”, and used to set the detection_direction value as seen in Figure 3.

Knowing a rule’s “detection direction” is important in being able to determine the significance and seriousness of what it is detecting. For example, consider a rule that detects traffic known to be generated by devices infected with the Mirai malware. Such traffic seen inbound (coming from EXTERNAL_NET and directed to HOME_NET) can usually be classified as scanning and considered to be little more than Internet noise. Yet such traffic seen outbound (coming from HOME_NET and directed to EXTERNAL_NET), is a good indication that there is an infected device on your network and it is part of an active botnet. The latter case is more serious than the former and should be treated as such. The rule and its associated IDS alert need to be able to communicate these realities. Accurately classifying rules and their IDS alerts so that they can be programmatically responded to is important, and this is where Post Filter Modification comes into play.
PFMod (Post Filter Modification)
Aristotle v2 offers the option to further filter and modify the ruleset after normalization, enhancement, and initial filter string application. This is known as PFMod (Post Filter Modification) and allows for the identification of rules based on filter strings, and then particular “actions” taken on those rules.
PFMod Actions
PFMod actions include the ability to add/delete metadata, enable/disable rules, set priority, and do a regular expression based “find and replace” on the full rule. Supported PFMod actions include:
- disable: Disable the rule.
- enable: Enable the rule. Note that for “disabled” rules to make it to PFMod for consideration, they must first match in the initial filter string matching phase.
- add_metadata: YAML key-value pair where the (YAML) value is the metadata key-value pair to add, e.g. “protocols http”. Note that if there is already metadata using the given key, it is not overwritten unless the value is the same too, in which case nothing is added since it already exists.
- add_metadata_exclusive: YAML key-value pair where the (YAML) value is the metadata key-value pair to add (e.g., “priority high”). If the given metadata key already exists, overwrite it with the new value.
- delete_metadata: If a metadata key-value pair is given (e.g., “former_category malware”), remove the key-value pair from the rule. If just a metadata key name is given (e.g., “former_category”), remove all metadata using the given key, regardless of the value(s).
- regex_sub: Perform a regular expression find and replace on the rule.
- set_<keyword>: Set the <keyword> in the IDS rule string to have the given value. If the rule does not contain the given keyword, add it and set the value to the given value. Supported keywords include “priority,” “sid,” “gid,” “rev,” “msg,” “classtype,” “reference,” “target,” “threshold,” and “flow.” For integer keywords (“priority,” “rev,” “gid,” and “sid”), relative values can be used by preceding the integer value with a ‘+’ or ‘-’. For example, the action ‘set_priority “-1″‘ will cause the existing priority value in the rule to be decreased by 1.
- set_<arbitrary_integer_metadata>: Similar to “add_metadata_exclusive,” allows for the setting or changing of an arbitrary integer-based metadata key value, but also supports relative values, along with default values. Format shown in Figure 4.

Notes:
- The <arbitrary_integer_metadata> string corresponds to the metadata key name and must contain at least one underscore (‘_’) character.
- The metadata key being referenced should have a value corresponding to an integer.
- A preceding ‘+’ or ‘-‘ to the given <value> will cause the existing metadata value in the rule to be increased or decreased by the given <value>, respectively. If the metadata key does not exist, then the value will be set to the given <default> value, if provided, otherwise no change will be made.
- Examples show in Figure 5.

PFMod Rules
PFMod conditions and actions are controlled by PFMod rules (not to be confused with IDS “rules”). PFMod rules are defined in YAML files and are processed in a depth-first, linear fashion. This means that you can define actions that apply broadly to many (or all) rules, and then have more specific PFMod rules that apply more precise actions to subsets of those rules. As shown in Figure 6, PFMod rules files can “include” other PFMod rules files for easy organization.

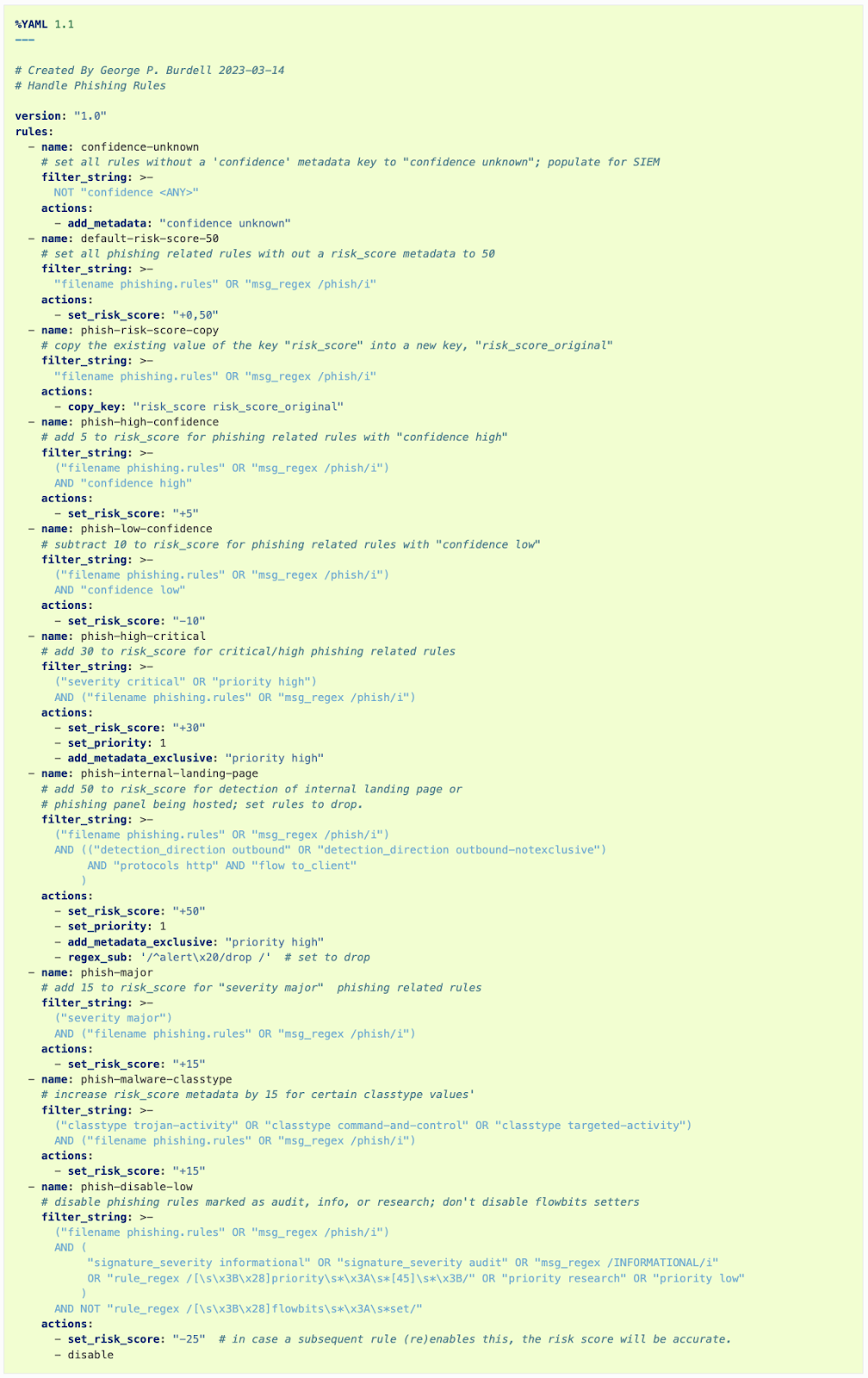
In addition to include statements, a PFMod rule file can contain multiple rules. Figure 7 shows an example PFMod rule file that updates IDS rules and metadata.
Risk Score
Each Suricata rule that is deployed at Uber receives a “risk score.” These risk scores are automatically generated at ruleset compile time and applied as metadata values by PFMod rules. Rule metadata, including risk_score, are included in Suricata alerts and play an important role in event processing. More on this later.
Maintenance
When new rules are added to the rulesets used at Uber—which happens daily—they are automatically subjected to our existing Aristotle v2 pipeline which includes filtering and the application of non-trivial PFMod logic to shape and classify each rule accordingly. Thus, manual analysis and tweaking of each new rule is avoided by using Aristotle v2 as a reliable “set it and forget it” mechanism. Of course, judicious occasional revisiting of ruleset filtering and PFMod logic is done to align the ruleset with the current environments and expected traffic patterns.
Documentation
More details about Aristotle v2 and how to use it can be found in the online documentation.
Aggregation, Correlation, Risk Score, and Alerting
Uber processes billions of events a day, including hundreds of thousands of IDS alerts. Events come from myriad sources including log files, vendor products, in-house systems, custom detections, and sensing technologies like IDS. Security related events, referred to as “signals,” receive a “risk score” value that is represented by a single integer and associated with the signal. The risk score value for a signal plays a non-trivial role in downstream aggregation and correlation algorithms that ultimately determine if a signal or group of signals qualify for a formal meta-alert requiring a response. In other words, the “risk score” value quantifies the necessity and appropriate level of response. Depending on the level warranted, responses typically take the form of a manual investigation by a security analyst, and/or a series of programmatic actions in a Security Orchestration And Response (SOAR) pipeline.
The evaluation, aggregation, and correlation of signals at Uber is a sophisticated process (not to mention the response pipelines), the intricate details of which are outside the scope of this article. However, the general strategy revolves around what we call “Entity Based Alerting.” For a given time window, signals are grouped by entity (e.g., IP address, host, user, etc.) and a correlation algorithm is applied to determine if an actionable meta-alert should be created. The risk score values from individual signals play a significant part in this calculation, as they are weighted and added together, and ultimately compared against a threshold used to make a final determination. The weighting of signals—which can be thought of as adjusting risk scores up or down—is based on sundry criteria, including entity characteristics, and often involves correlation with other data sources. For example, signals for a user entity where the user is an Administrator are weighted higher than those related to a non-Administrator user. Similarly, a signal involving an IP address entity from a known sanctioned vulnerability scanner will be weighted lower, while an event involving an IP address entity that is known to be part of an isolated network responsible for financial transactions will be weighted higher. Note that given a high enough risk score and/or weighting modification, a single signal can be enough to generate a meta-alert and response.
In practice, aggregating and correlating signals related to common entities has shown to be an effective way to identify events and combinations of events worth responding to. With IDS alerts, Aristotle v2 plays a crucial role in being able to choose which rules are enabled, what metadata is included, and what risk score value each rule should carry. IDS alert metadata, especially the risk score value, allows Suricata alerts to be better managed so that analysts are not overwhelmed with alerts or false positives.
Conclusion
By using Aristotle v2 to normalize, enhance, and manipulate rule metadata, rules can be accurately described, programmatically understood, and willfully modified. Applying concrete boolean algebra against metadata key-value pairs results in powerful filtering capabilities that allow us to curate Suricata rulesets to only run applicable rules in particular environments. Rules are automatically tuned based on explicit and inferred teleological motivations and ontological realities. Custom metadata values such as “risk_score” are intelligently added to each rule which enables effective downstream correlation such that false positives are minimized and notable alerts receive appropriate attention. The result is a scalable, controllable, and accurate Suricata ruleset management and response solution.
[ad_2]
Source link

