

[ad_1]
Introduction
Last week, we explored LedgerStore (LSG) – Uber’s append-only, ledger-style database. This week, we’ll dive into how we migrated Uber’s business-critical ledger data to LSG. We’ll detail how we moved more than a trillion entries (making up a few petabytes of data) transparently and without causing disruption, and we’ll discuss what we learned during the migration.
History
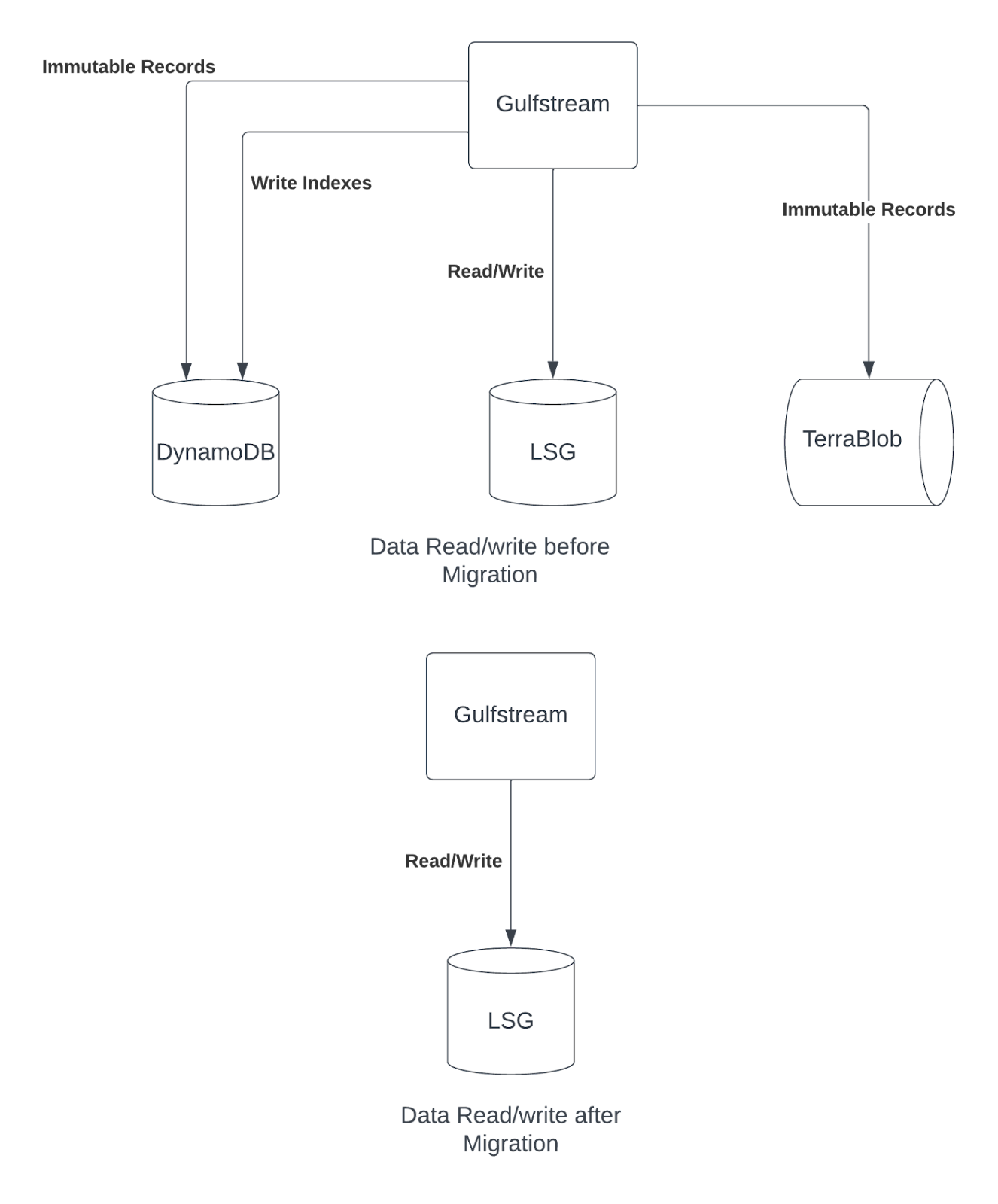
Gulfstream is Uber’s payment platform. It was launched in 2017 using DynamoDB for storage. At Uber’s scale, DynamoDB became expensive. Hence, we started keeping only 12 weeks of data (i.e., hot data) in DynamoDB and started using Uber’s blobstore, TerraBlob, for older data (i.e., cold data). TerraBlob is similar to AWS S3.
For a long-term solution, we wanted to use LSG. It was purpose-built for storing payment-style data. Its key features are:
- It is verifiably immutable (i.e., you can check that records have not been altered using cryptographic signatures)
- Tiered storage to manage cost (the hot data is kept at a place that is best to serve requests and cold data is stored at a place that is optimized for storage)
- Better lag for eventually consistent secondary indexes
So, by 2021, Gulfstream was using a combination of DynamoDB, TerraBlob, and LSG to store data.
- DynamoDB for the last 12 weeks of data
- TerraBlob, Uber’s internal blob store, for cold data
- LSG, where we were writing data, and wanted to migrate to it
Why Migrate?
LSG is better suited for storing ledger-style data because of its immutability. The recurring cost savings by moving to LSG were significant.
Going from three to a single storage would simplify the code and design of the Gulfstream services responsible for interacting with storage and creating indexes. This in turn makes it easy to understand and maintain the services.
LSG promised shorter indexing lag (i.e., time between when a record is written and its secondary index is created). Additionally, it would give us faster network latency because it was running on-premises within Uber’s data centers.
Nature of Data & Associated Risk
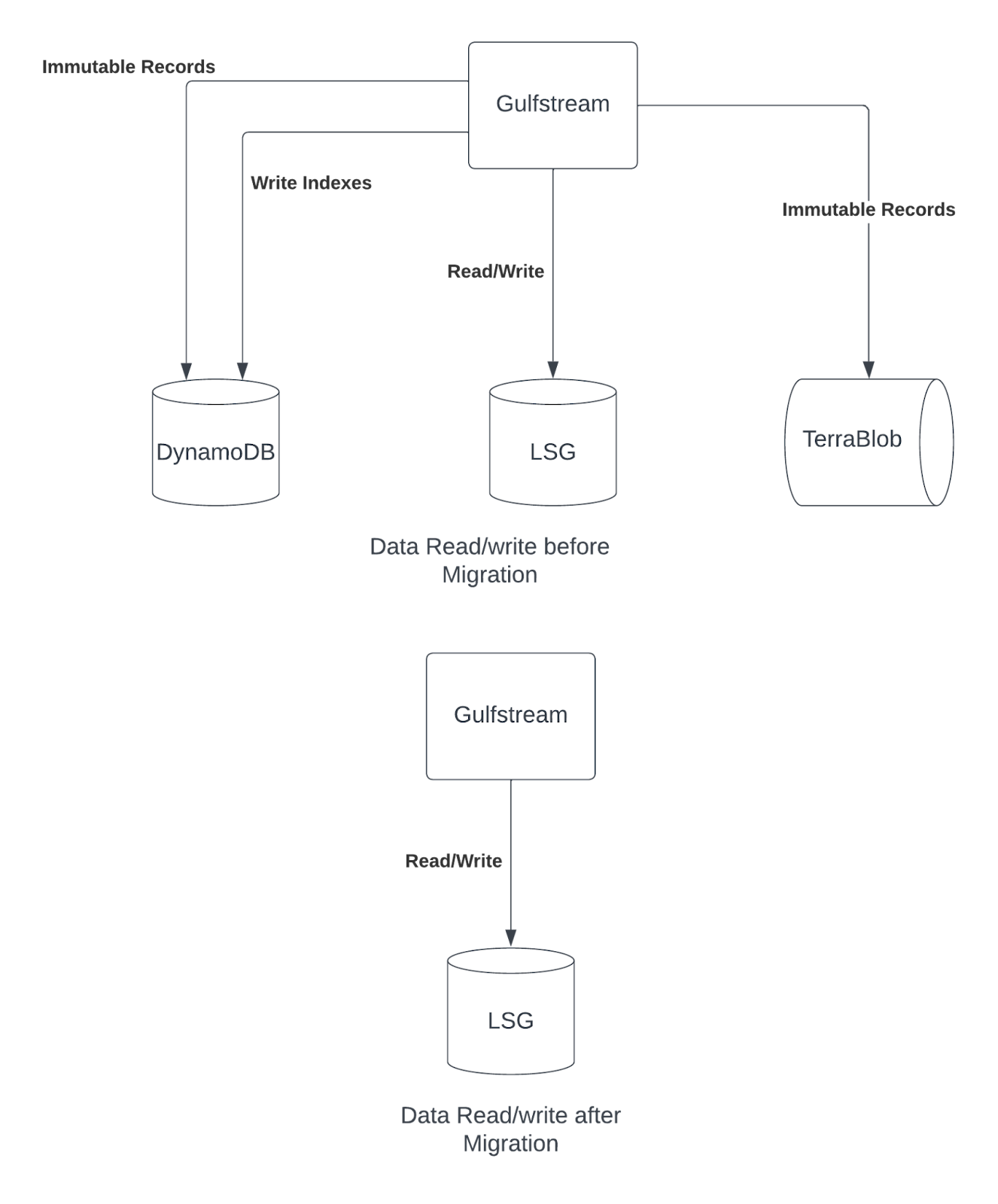
The data we were migrating is all of Uber’s ledger data for all of Uber’s business since 2017:
- Immutable records – 1.2 PB compressed size
- Secondary indexes – 0.5 PB uncompressed size
Immutable records should not be modified. So, for all practical purposes, once we have written a record, it can’t be changed. We do have the flexibility of modifying secondary index data for correcting problems.
Checks
To ensure that the backfill is correct and acceptable in all respects, we need to check that we can handle the current traffic and the data that is not being accessed currently is correct. The criteria for this was:
- Completeness: All the records were backfilled.
- Correctness: All the records were correct.
- Load: LSG should be able to handle current load.
- Latency: The P99 latency of LSG was within acceptable bounds.
- Lag: The secondary indexes are created in the background. We want to make sure that the delay of the index creation process was within acceptable limits.
The checks were done using a combination of shadow validation and offline validation.
Shadow Validation
This compares the response that we had been returning before migration with the one that we would return with the LSG as data source. This helps us ensure that our current traffic will be disrupted by neither data migration issues nor code bugs. We wanted our backfill to be at least 99.99% complete and correct as measured by shadow validation. We also had a 99.9999% upper bound for the same. The reason for having an upper bound are:
- When migrating historical data, there are always data corruption issues. Sometimes this is because data was not written correctly during the initial development time of the service. It is also possible to see data corruption because of scale. As an example, S3 gives 11 nines of durability guarantee then you can expect 10 corruptions in 1 trillion records.
- Indexes are eventually consistent, which means that some records will appear after a few seconds. So, the shadow validation will flag them as missing. This is a false positive that shows up at a large scale.
- For 6 nines, you have to look at data of 100 million comparisons to give any results with good confidence. This means if your shadow validation is comparing 1,000 records/second, then you need to wait for a bit more than one day just to collect sufficient data. With 7 nines, you will have to wait 12 days. In practical terms this would slow the project to a halt.
- With a well-defined upper bound, you are not forced to look at every potential issue that you suspect. Say if the occurrence of a problem is 1/10 of the upper bound, you need not even investigate it.
- With 6 nines, we could end up with slightly more than 1 million corrupt records. Even though 6 nines of confirmed correctness could mean a real cost to the company, the savings generated by this project outweighed the potential cost.
During shadow validation you are essentially duplicating production traffic on LSG. So by monitoring LSG, we can verify that it can handle our production traffic while meeting our latency and lag requirements. It gives us good confidence in the code that we wrote for accessing the data from LSG. Additionally, it also gives us some confidence about completeness and correctness of data, particularly with data that is currently being accessed. We developed a single generic shadow validation code that was reused multiple times for different parts of the migration.
During the migration process we found latency and lag issues because of multiple bugs in different parts and fixed them.
- Partition key optimization for better distribution of index data
- Index issues causing scan of the record instead of point lookup
Unfortunately, live shadow validation can’t give strong guarantees about our corpus of rarely-accessed historical data.
Offline Validation & Incremental Backfill
This compares complete data from the LSG with the data dump from DynamoDB. Because of various data issues, you have to skip over bad records to ensure that your backfill can go through. Additionally, there can be bugs in the backfill job itself. Offline validation ensures that the data backfill has happened correctly and it covers complete data. This has to be done in addition to shadow validation because live traffic tends to access only recent data. So, if there are any problems lurking in the cold data that is infrequently accessed, it will not be caught by shadow validation.
The key challenge in offline validation is size of data. The biggest data that we tackled was 70 TB compressed (estimated 300 TB uncompressed) in size and we compared 760 billion records in a single job. This type of Apache SparkTM job requires data shuffling and Distributed Shuffle as a Service for Spark combined with Dynamic Resource Allocation and Speculative Execution let us do exactly that at a reasonable speed under resource constraints.
Offline validation found missing records and its output was used for incremental backfill. We iterated between offline validation and backfill to ensure that all the records were written.
Backfill Issues
Every backfill is risky. We used Uber’s internal offering of Apache Spark for the backfills. Here are the different problems that we encountered and how we handled them.
Scalability
You want to start at a small scale and scale up gradually till you hit the limit of the system. If you just blindly push beyond this point then you are effectively creating a DDoS attack on your own systems. At this point, you want to find the bottleneck, address it, and then scale up your job. Most of the time it’s just a matter of scaling up downstream services, other times it can be something more complex. In either case, you don’t want to scale your backfill job beyond the capability of the bottleneck of the system. It’s a good idea to scale up in small increments and monitor closely after each scale-up.
Incremental Backfills
When you try to backfill 3 years’ worth of data in say 3 months, you are generating traffic that puts 10x the normal traffic load and the system may not be able to cope with this traffic. As an example, you will need 120 days to backfill 100B records at 10K/sec rate when your production normally handles 1K/sec rate. So, you can expect the system to get overloaded. If there is even a remote chance of the backfill job causing an ongoing problem, you must shut it down. So, it is unrealistic to expect that a backfill job can run from start to finish in one go, and therefore you have to run backfills incrementally.
A simple and effective way to do this is to break the backfill into small batches that can be done one by one, such that each batch can complete within a few minutes. Since your job may shut down in the middle of a batch, it has to be idempotent. Every time you complete a batch you want to dump the statistics (such as records read, records backfilled, etc.) to a file. As your backfill continues, you can aggregate numbers from them to check the progress.
If you can delete or update existing records, it lowers the risk and cost of mistakes and code bugs during the backfill.
Rate Control
To backfill safely, you want to make sure that your backfill job behaves consistently. So, your job should have rate control that can be easily tweaked to scale up or scale down. In Java/Scala you can use Guava’s RateLimiter.
Dynamic Rate Control
In some cases, you may be able to go faster when there is less production traffic. For this you need to monitor the current state of the system and see if it’s ok to go faster. We adjusted RPS on the lines of additive increase/multiplicative decrease. We still had an upper bound on the traffic for safety.
Emergency Stop
The migration process needs the ability to stop backfill quickly in case there is an outage or even suspicion of overload. Any backfill during an outage has to be stopped as both a precaution and as a potential source of noise. Even post-outage, systems tend to get extra load as systems recover. Having the ability to stop backfill also helps debug scale-related issues.
Size of Data File
When dumping data, keep the size of the files to around 1GB with 10x flexibility on both sides. If the size of the file is too big, you run into issues such as MultiPart limitation of different tools. If your file size is small, then you have too many files and even listing them will take significant time. You may even start hitting ARGMAX limit of when running commands in a shell. This becomes significant enough to make sure that every time you do something with data it has been applied to all files and not just some of them.
Fault Tolerance
All backfill jobs need some kind of data transformation. When you do this you inevitably run into data quality/corruption issues. You can’t stop the backfill job every time this happens because such bad records tend to be randomly distributed. But you can’t ignore them as well because it might also be because of a code bug. To deal with this, you dump problematic records separately and monitor statistics. If the failure rate is high then you can stop the backfill manually, fix the problem, and continue. Otherwise, let the backfill continue and look at the failures in parallel.
Another reason for records not getting written is RPC timeout. You can retry for this, but at some point, you have to give up and move ahead irrespective of the reason to make sure you can make progress.
Logging
It is tempting to log during backfill to help with debugging and monitor progress, but this may not be possible because of the pressure that it will put on the logging infrastructure. Even if you can keep logs, there will be too much log data to keep around. The solution is to use a rate limiter to limit the amount of logs that you are producing. You need to rate limit only the parts that produce most of the logs. You can even choose to log all the errors if they happen infrequently.

Mitigating Risk
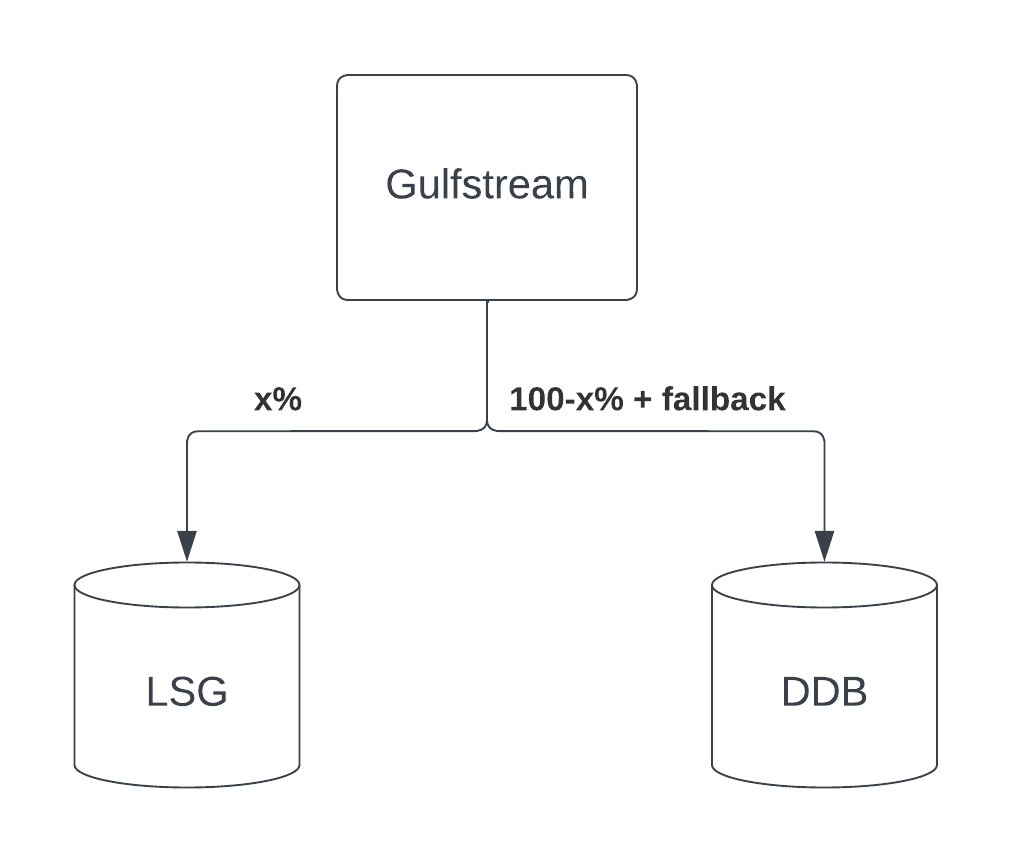
In addition to analyzing data from different validation and backfill stats we also were conservative with the rollout of LSG. We rolled it out over a few weeks and with go-aheads from on-call engineers of the major callers of our service. We initially rolled out with fallback (i.e., if the data was not found in LSG, we would try to fetch it from DynamoDB). We looked at the fallback logs before we removed the fallback. For every record that was flagged as missing in the fallback logs we checked LSG to make sure that it was not really missing. Even after that we kept the DynamoDB data around for a month before we stopped writing data to it, took a final backup, and dropped the table.
Conclusion
In this article, we covered the migration of massive amounts of business-critical money data from one datastore to another. We covered different aspects of the migration, including criteria for migration, checks, backfill issues, and safety. We were able to do this migration over two years without any downtime or outages during or after the migration.
Acknowledgments
Thanks to Amit Garg and Youxian Chen for helping us migrate the data from TerraBlob to LSG. Thanks to Jaydeepkumar Chovatia, Kaushik Devarajaiah, and Rashmi Gupta from the LSG team for supporting us throughout this work. Thanks to Menghan Li for migrating data for Uber Cash’s ledger.
Cover photo attribution: “Waterfowl Migration at Sunset on the Huron Wetland Management District” by USFWS Mountain Prairie is marked with Public Domain Mark 1.0.
Amazon Web Services, AWS, the Powered by AWS logo, [and name any other AWS Marks used in such materials] are trademarks of Amazon.com, Inc. or its affiliates.
Apache®, Apache SparkTM, and SparkTM are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks.
[ad_2]
Source link

