

[ad_1]
Introduction
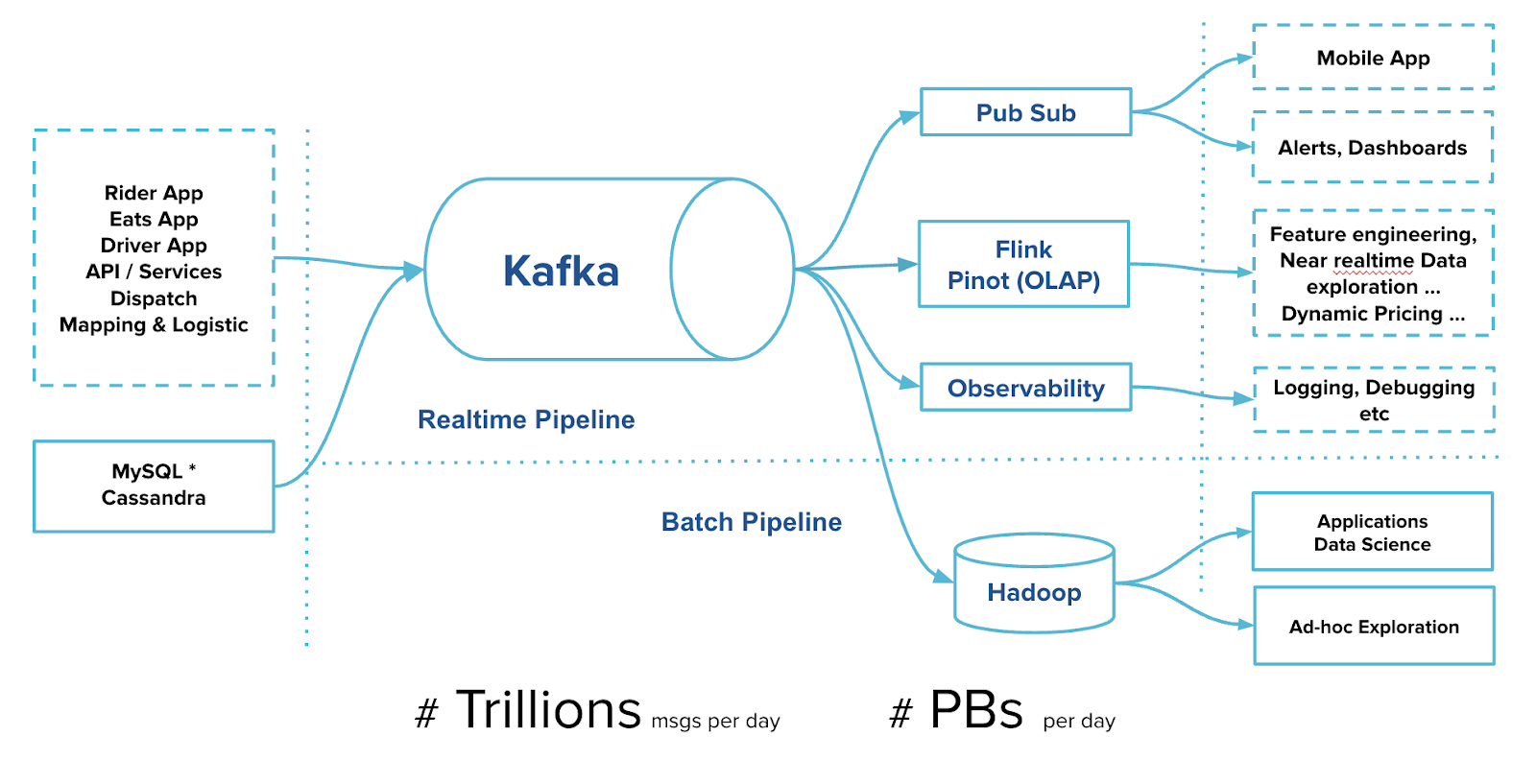
Apache Kafka® is the cornerstone of Uber’s tech stack. It plays an important role in powering several critical use cases and is the foundation for batch and real-time systems at Uber.
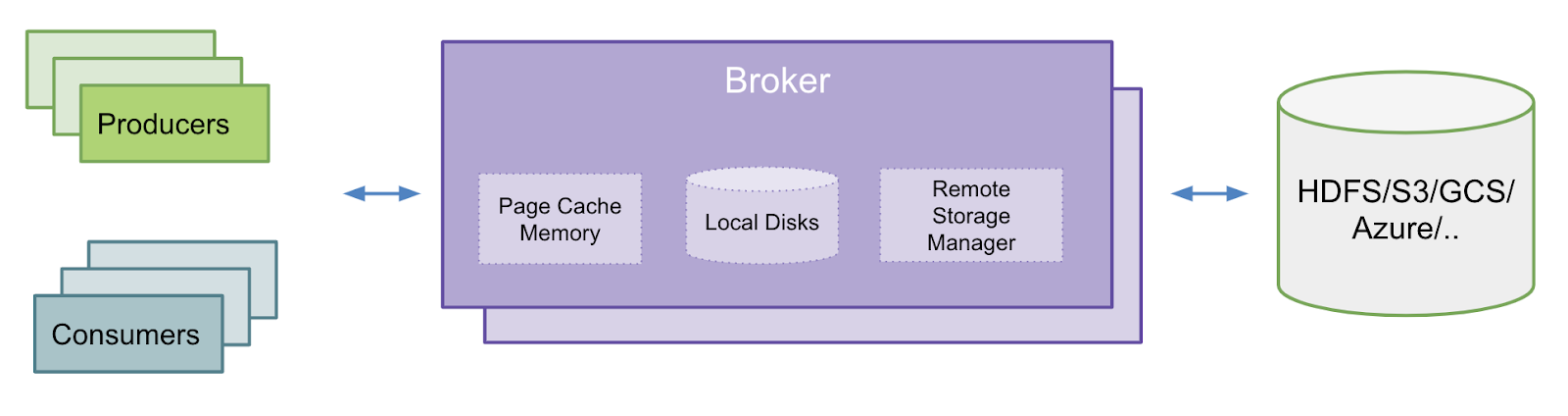
Kafka stores the messages in append-only log segments on the broker’s local storage. Each topic can be configured with the targeted retention based on size or time. It gives guarantees for users to consume the data within the retention period or size even when the respective consuming applications fail or become slow for several reasons. Total storage on a cluster depends upon factors like the total number of topic partitions, produce throughput, and retention configuration. A Kafka broker typically needs to have larger storage to support the required topic partitions hosted on a broker.
Motivation/Background Behind Project
Kafka cluster storage is typically scaled by adding more broker nodes to the cluster. But this also adds needless memory and CPUs to the cluster, making overall storage cost less efficient compared to storing the older data in external storage. A larger cluster with more nodes also adds to the deployment complexity and increases operational costs because of the tight coupling of storage and processing. So, it brings several issues related to scalability, efficiency, and operations.
We proposed Kafka Tiered Storage (KIP-405) to avoid tight coupling of storage and processing in a broker. It provides two tiers of storage, called local and remote. These two tiers can have respective retention policies based on the respective use cases.
Goals
Below are the main goals that we set for tiered storage:
- Extend the storage beyond the broker
- Memory/PageCache
- Local storage
- Remote storage support (including cloud/object stores like S3/GCS/Azure)
- Durability and Consistency semantics similar to local storage
- Isolation of reading latest and historical data
- No changes are required from clients
- Easy tuning and provisioning of clusters
- Improve operational and cost efficiency
Architecture
Kafka cluster enabled with tiered storage is configured with two tiers of storage called local and remote. The local tier is the broker’s local storage where the segments are stored currently. The new remote tier is the extended storage, such as HDFS/S3/GCS/Azure. Both these tiers will have respective retention configurations based on size and time. The retention period for the local tier can be significantly reduced from days to a few hours. The retention period for the remote tier can be much longer–days, or even months. Applications sensitive to latency conduct tail reads and are catered to from the local tier, utilizing Kafka’s efficient page cache utilization for data retrieval. On the other hand, applications such as backfill or those recovering from failures requiring older data than what’s locally available, are served from the remote tier.
This approach enables the scalability of storage in a Kafka cluster without being tied to memory and CPU resources, thus transforming Kafka into a viable long-term storage option. Moreover, it decreases the local storage burden on Kafka brokers, consequently reducing the data to be transferred during recovery and rebalancing. Log segments accessible in the remote tier don’t require restoration on the broker and can be accessed directly from the remote tier. It eliminates the necessity to expand the Kafka cluster storage and add new nodes when extending the retention period. Additionally, it allows for significantly longer data retention without the requirement for separate data pipelines to transfer data from Kafka to external storage (a common practice in many current setups).
Tiered storage divides a topic partition’s log into two different logical components called local log and remote log. Local log contains a list of local log segments and remote log contains a list of remote log segments. The remote log subsystem copies each topic partition’s eligible segments from local storage to the remote storage. A segment is eligible to be copied when its end offset is less than LastStableOffset of a partition.
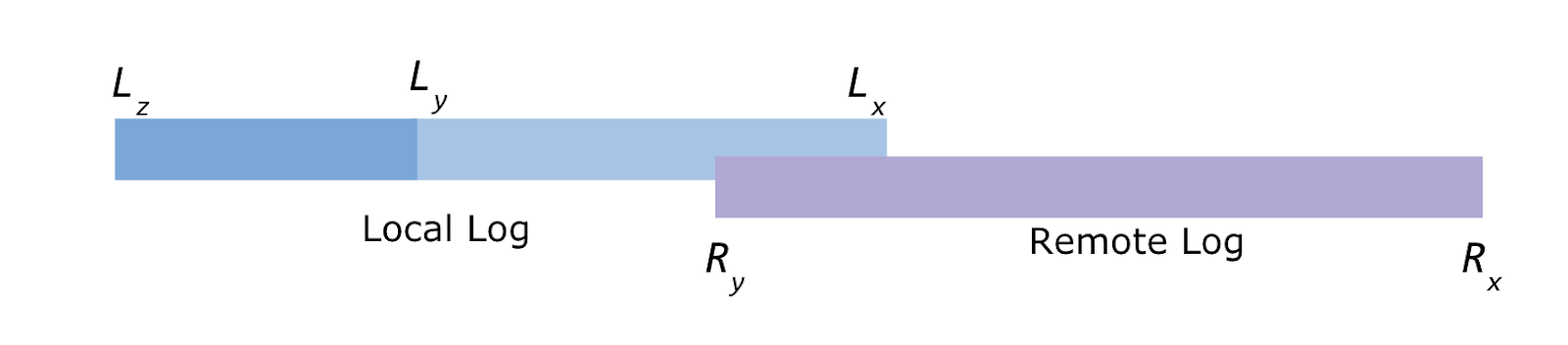
Lx = Local log start offset Lz = Local log end offset Ly = Last stable offset(LSO)
Ry = Remote log end offset Rx = Remote log start offset
Lz >= Ly >= Lx and Ly >= Ry >= Rx
Apache Kafka storage subsystem maintains the above offset constraints for local and remote log segments of a topic partition.
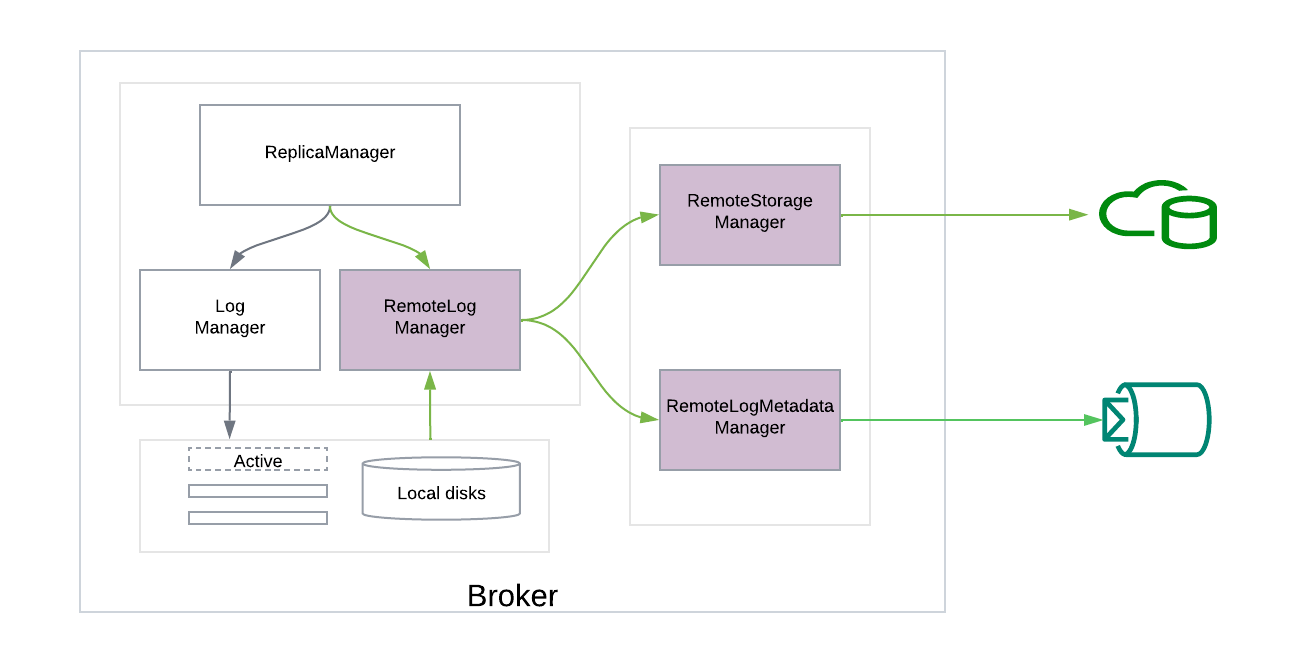
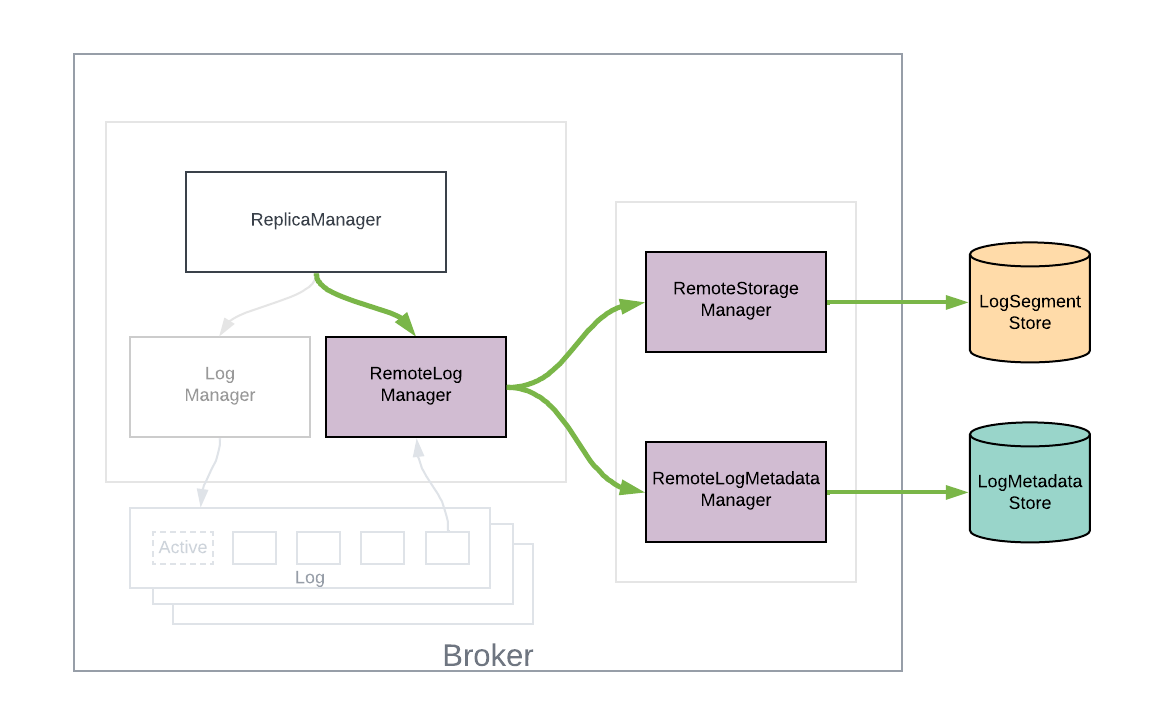
The above diagram gives a high-level overview of the new architecture with newly introduced components:
- RemoteStorageManager
- RemoteLogMetadataManager
- RemoteLogManager
We introduced two pluggable components within the storage layer called RemoteStorageManager and RemoteLogMetadataManager. These can be implemented by developers based on their targeted storage systems and plugged into their Kafka environments.
RemoteStorageManager interface provides the actions for remote log segments that include copy, fetch, and delete from remote storage.
RemoteLogMetadataManager interface provides the lifecycle operations of metadata about remote log segments with strongly consistent semantics. There is a default implementation that uses an internal topic. Users can plugin their implementation if they intend to use another system to store remote log segment metadata.
RemoteLogManager is a logical layer responsible for managing the life cycle of remote log segments. That includes:
- Copying segments to the remote storage
- Cleaning up of expired segments in the remote storage
- Fetching the data from remote storage
It also uses the pluggable remote storage components as and when needed. Each remote log segment is identified with a unique identifier called RemoteLogSegmentId, even for the same topic partition and offsets.
Copying Segments to Remote Storage
Each topic partition stores data in a logical log, which contains a sequence of physical log segments with the respective auxiliary files like segment indexes, producer state snapshots, and leader epoch checkpoints. Each partition replica creates these log segments, flushes them to disk and rolls over the segment based on segment roll configurations based on size or time. A log segment is eligible if its end offset is less than the last-stable-offset of the partition. The broker acting as a leader for a topic partition is responsible for copying the eligible log segments to the remote storage. It copies the log segments from the earliest segment to the latest segment in a sequence. It uses RemoteStorageManager for copying the segment with its indexes like offset, timestamp, producer snapshot, and its respective leader epoch cache. It also adds and updates entries in RemoteLogMetadataManager with respective states for each copied segment.
The below diagram shows the sequence of copying the segments by maintaining local and remote log segments:
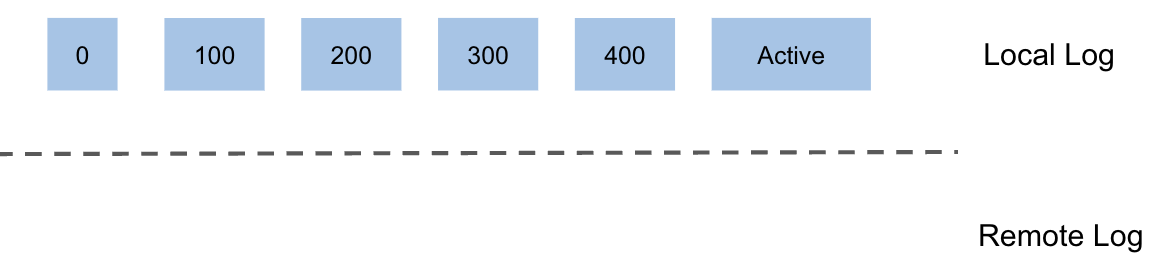
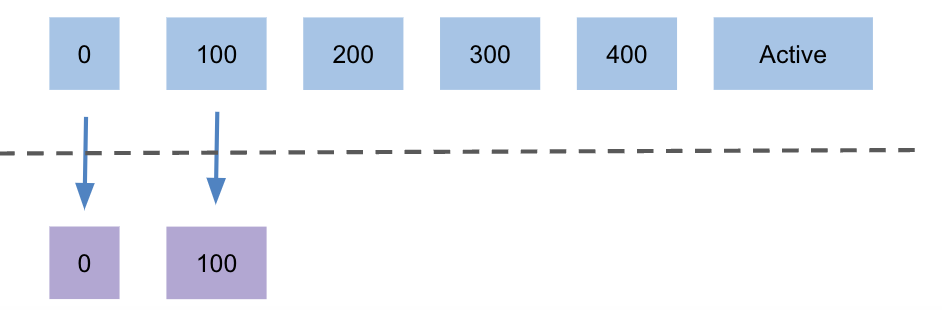

Cleaning up of Remote Segments
As mentioned earlier, each topic will have a retention configuration based on size and time for both local data and remote data. Remote data is cleaned up at regular intervals by computing the eligible segments by a dedicated thread pool. This is different from the asynchronous cleaning up of the local log segments. When a topic is deleted, cleaning up of remote log segments is done asynchronously and it will not block the existing delete operation or recreate a new topic.
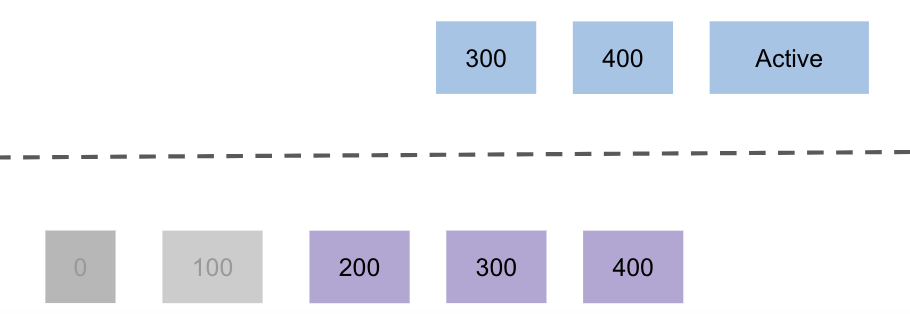
Fetching Segments from Remote Storage
When a consumer fetch request is received and it is only available only in remote storage, then it is served using a dedicated thread pool. If the targeted offset is available in the broker’s local storage, then it is served using the existing local fetch mechanism. So, a broker separates the local reads from remote reads and they will not block each other.
RemoteLogManager determines the targeted remote segment based on the desired offset and leader epoch by looking into the metadata store using RemoteLogMetadataManager. It uses RemoteStorageManager to find the position within the segment and start fetching the desired data.
Follower Replication
Followers replicate the data from a leader to become an in-sync replica. They need to maintain the message lineage across a sequence of log segments as the leader. They may also do truncation of the segments if needed to maintain the message ordering.
With tiered storage, follower replicas need to replicate the segments that are available on the leader’s local storage. Each log also needs auxiliary data like leader epoch state and producer-ID snapshots. So, a follower needs to build this auxiliary data before it starts fetching any messages from the leader. The follower fetch protocol makes sure to maintain the consistency and ordering of messages across all the replicas irrespective of changes in the cluster like broker replacements, failures, etc. If you are interested in understanding the inner workings of the enhanced follower fetch protocol, you can read it in the original document to understand the detailed design and how it handles several scenarios.
Conclusion
In this blog, we covered an introduction and high-level architecture of tiered storage at Uber. If you are interested in more details, you can read the detailed design in KIP-405. Most of this work was done collaborating with the Apache Kafka community. The major part of this feature is available as early access in Apache Kafka 3.6.0. This feature has been running in production for ~1-2 years in different workloads respectively. In the next part of this blog series we will cover our production experience and how it helped with better reliability, scalability, and efficiency of our clusters.
Apache®, Apache Kafka™, and Kafka™ are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks.
[ad_2]
Source link

