

[ad_1]

|
Amazon Managed Streaming for Apache Kafka (Amazon MSK) provides a fully managed and highly available Apache Kafka service simplifying the way you process streaming data. When using Apache Kafka, a common architectural pattern is to replicate data from one cluster to another.
Cross-cluster replication is often used to implement business continuity and disaster recovery plans and increase application resilience across AWS Regions. Another use case, when building multi-Region applications, is to have copies of streaming data in multiple geographies stored closer to end consumers for lower latency access. You might also need to aggregate data from multiple clusters into one centralized cluster for analytics.
To address these needs, you would have to write custom code or install and manage open-source tools like MirrorMaker 2.0, available as part of Apache Kafka starting with version 2.4. However, these tools can be complex and time-consuming to set up for reliable replication, and require continuous monitoring and scaling.
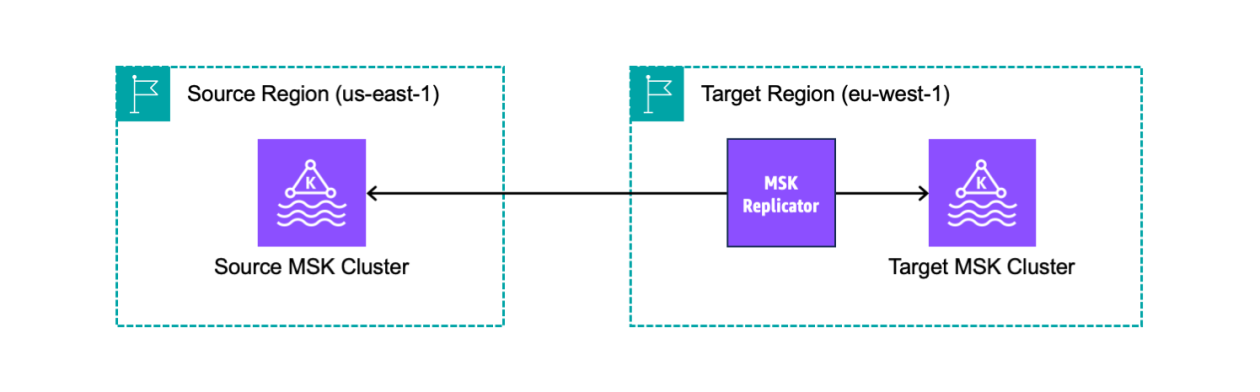
Today, we’re introducing MSK Replicator, a new capability of Amazon MSK that makes it easier to reliably set up cross-Region and same-Region replication between MSK clusters, scaling automatically to handle your workload. You can use MSK Replicator with both provisioned and serverless MSK cluster types, including those using tiered storage.
With MSK Replicator, you can setup both active-passive and active-active cluster topologies to increase the resiliency of your Kafka application across Regions:
- In an active-active setup, both MSK clusters are actively serving reads and writes.
- In an active-passive setup, only one MSK cluster at a time is actively serving streaming data while the other cluster is on standby.
Let’s see how that works in practice.
Creating an MSK Replicator across AWS Regions
I have two MSK clusters deployed in different Regions. MSK Replicator requires that the clusters have IAM authentication enabled. I can continue to use other authentication methods such as mTLS or SASL for my other clients. The source cluster also needs to enable multi-VPC private connectivity.

From a network perspective, the security groups of the clusters allow traffic between the cluster and the security group used by the Replicator. For example, I can add self-referencing inbound and outbound rules that allow traffic from and to the same security group. For simplicity, I use the default VPC and its default security group for both clusters.
Before creating a replicator, I update the cluster policy of the source cluster to allow the MSK service (including replicators) to find and reach the cluster. In the Amazon MSK console, I select the source Region. I choose Clusters from the navigation pane and then the source cluster. First, I copy the source cluster ARN at the top. Then, in the Properties tab, I choose Edit cluster policy in the Security settings. There, I use the following JSON policy (replacing the source cluster ARN) and save the changes:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "kafka.amazonaws.com"
},
"Action": [
"kafka:CreateVpcConnection",
"kafka:GetBootstrapBrokers",
"kafka:DescribeClusterV2"
],
"Resource": "<SOURCE_CLUSTER_ARN>"
}
]
}I select the target Region in the console. I choose Replicators from the navigation pane and then Create replicator. Here, I enter a name and a description for the replicator.

In the Source cluster section, I select the Region of the source MSK cluster. Then, I choose Browse to select the source MSK cluster from the list. Note that Replicators can be created only for clusters that have a cluster policy set.

I leave Subnets and Security groups as their default values to use my default VPC and its default security group. This network configuration may be used to place elastic network interfaces (EINs) to facilitate communication with your cluster.
The Access control method for the source cluster is set to IAM role-based authentication. Optionally, I can turn on multiple authentication methods at the same time to continue to use clients that need other authentication methods like mTLS or SASL while the Replicator uses IAM. For cross-Region replication, the source cluster cannot have unauthenticated access enabled, because we use multi-VPC to access their source cluster.

In the Target cluster section, the Cluster region is set to the Region where I’m using the console. I choose Browse to select the target MSK cluster from the list.

Similar to what I did for the source cluster, I leave Subnets and Security groups as their default values. This network configuration is used to place the ENIs required to communicate with the target cluster. The Access control method for the target cluster is also set to IAM role-based authentication.

In the Replicator settings section, I use the default Topic replication configuration, so that all topics are replicated. Optionally, I can specify a comma-separated list of regular expressions that indicate the names of the topics to replicate or to exclude from replication. In the Additional settings, I can choose to copy topics configurations, access control lists (ACLs), and to detect and copy new topics.

Consumer group replication allows me to specify if consumer group offsets should be replicated so that, after a switchover, consuming applications can resume processing near where they left off in the primary cluster. I can specify a comma-separated list of regular expressions that indicate the names of the consumer groups to replicate or to exclude from replication. I can also choose to detect and copy new consumer groups. I use the default settings that replicate all consumer groups.

In Compression, I select None from the list of available compression types for the data that is being replicated.

The Amazon MSK console can automatically create a service execution role with the necessary permissions required for the Replicator to work. The role is used by the MSK service to connect to the source and target clusters, to read from the source cluster, and to write to the target cluster. However, I can choose to create and provide my own role as well. In Access permissions, I choose Create or update IAM role.

Finally, I add tags to the replicator. I can use tags to search and filter my resources or to track my costs. In the Replicator tags section, I enter Environment as the key and AWS News Blog as the value. Then, I choose Create.

After a few minutes, the replicator is running. Let’s put it into use!
Testing an MSK Replicator across AWS Regions
To connect to the source and target clusters, I already set up two Amazon Elastic Compute Cloud (Amazon EC2) instances in the two Regions. I followed the instructions in the MSK documentation to install the Apache Kafka client tools. Because I am using IAM authentication, the two instances have an IAM role attached that allows them to connect, send, and receive data from the clusters. To simplify networking, I used the default security group for the EC2 instances and the MSK clusters.
First, I create a new topic in the source cluster and send a few messages. I use Amazon EC2 Instance Connect to log into the EC2 instance in the source Region. I change the directory to the path where the Kafka client executables have been installed (the path depends on the version you use):
To connect to the source cluster, I need to know its bootstrap servers. Using the MSK console in the source Region, I choose Clusters from the navigation page and then the source cluster from the list. In the Cluster summary section, I choose View client information. There, I copy the list of Bootstrap servers. Because the EC2 instance is in the same VPC as the cluster, I copy the list in the Private endpoint (single-VPC) column.

Back to the EC2 instance, I put the list of bootstrap servers in the SOURCE_BOOTSTRAP_SERVERS environment variable.
Now, I create a topic on the source cluster.
Using the new topic, I send a few messages to the source cluster.
Let’s see what happens in the target cluster. I connect to the EC2 instance in the target Region. Similar to what I did for the other instance, I get the list of bootstrap servers for the target cluster and put it into the TARGET_BOOTSTRAP_SERVERS environment variable.
On the target cluster, the source cluster alias is added as a prefix to the replicated topic names. To find the source cluster alias, I choose Replicators in the MSK console navigation pane. There, I choose the replicator I just created. In the Properties tab, I look up the Cluster alias in the Source cluster section.

I confirm the name of the replicated topic by looking at the list of topics in the target cluster (it’s the last one in the output list):
Now that I know the name of the replicated topic on the target cluster, I start a consumer to receive the messages originally sent to the source cluster:
Note that I can use a wildcard in the topic subscription (for example, .*my-topic) to automatically handle the prefix and have the same configuration in the source and target clusters.
As expected, all the messages I sent to the source cluster have been replicated and received by the consumer connected to the target cluster.
I can monitor the MSK Replicator latency, throughput, errors, and lag metrics using the Monitoring tab. Because this works through Amazon CloudWatch, I can easily create my own alarms and include these metrics in my dashboards.
To update the configuration to an active-active setup, I follow similar steps to create a replicator in the other Region and replicate streaming data between the clusters in the other direction. For details on how to manage failover and failback, see the MSK Replicator documentation.
Availability and Pricing
MSK Replicator is available today in: US East (Ohio), US East (N. Virginia), US West (Oregon), Asia Pacific (Singapore), Asia Pacific (Sydney), Europe (Frankfurt), and Europe (Ireland).
With MSK Replicator, you pay per GB of data replicated and an hourly rate for each Replicator. You also pay Amazon MSK’s usual charges for your source and target MSK clusters and standard AWS charges for cross-Region data transfer. For more information, see MSK pricing.
Using MSK replicators, you can quickly implement cross-Region and same-Region replication to improve the resiliency of your architecture and store data close to your partners and end users. You can also use this new capability to get better insights by replicating streaming data to a single, centralized cluster where it is easier to run your analytics.
Simplify your data streaming architectures using Amazon MSK Replicator.
— Danilo
[ad_2]
Source link


