

[ad_1]
Introduction
The Machine Learning (ML) team at Uber is consistently developing new and innovative components to strengthen our ML Platform (Michelangelo). In 2022, we took on a new and exciting challenge by making an investment into embeddings₁ , with a focus on Two-Tower Embeddings (TTE)₂. These embeddings create a magical experience by helping customers find what they’re looking for faster and easier. Specifically, we focused on the modeling and infrastructure to build out Uber’s first TTE model. We then used that to power our recommendation systems by generating and applying embeddings for eaters and stores.
Easy, right? Just kidding, but here’s a simple example of how it works for you. Recommendation systems are critical in helping users like yourself discover and obtain a wide range of goods and services on our platform. At Uber, our systems are designed to optimize every step, starting from when you first open the app and see your home feed. The order of restaurants on this feed is fueled by various rankers that generate the most relevant candidates (stores) to show you. The TTE model generates embeddings about both you, as well as the stores, and then feeds that information into the rankers to identify the best matches while simultaneously cutting down on computing time.
Of course, new innovations also come with new bugs, challenges, and setbacks, but that is just part of the fun! Our team wasn’t going to give up easily, so nearly a year later our Two-Tower Embeddings approach launched and unlocked major scalability and reusability wins, on top of impressive performance improvements.
This blog will cover what embeddings are, our architecture, challenges, and the thousands city-wide models we developed before we reached our single, global contextual model. Read on to learn the results of these wins, and what’s coming up next (spoiler: we aren’t just going to stop here)!
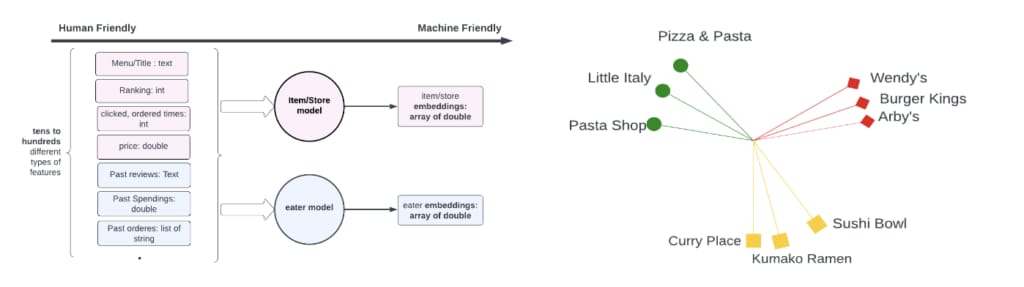
₁ An embedding is a rich representation for any entity such as: stores, eaters, items, drivers, locations, etc. It transforms human-friendly features (i.e., store menu, item price, eater preferred cuisine and past orders, etc.) into machine-learning-friendly vectors.
₂ Two-tower embeddings are the embeddings generated by a special deep learning architecture named two towers [ref]. TTE model architecture usually consists of a query tower and an item tower: query tower encodes search query and user profile to query embeddings, and item tower encodes store, grocery item, geo location to item embeddings.
What are Embeddings and Two-Tower Embeddings (TTE)?
An embedding is a rich representation for any entity via d-dimensional latent variables; these entities include, but are not limited to: stores, eaters, items, drivers, locations, and so on. It generally transforms human-friendly features, such as store menu, store price, store review, item title and description, item price, location’s full address, eater preference cuisine and past orders, rider preferred drop-offs and so on, to machine-learning-friendly dense vectors. These vectors can be directly used in any ML task (such as clustering, nearest neighbor search, classification, and so on) without too much feature engineering.

Two-tower embeddings are the embeddings generated by a special DL architecture named two towers. TTE model architecture usually consists of a query tower and an item tower: the query tower encodes search query and user profile to query embeddings, and the item tower encodes store, grocery item, and geo-location-to-item embeddings. The probability of engagement between the query and item is computed via the dot product (or cosine similarity, Euclidean distance, Hadamard product) between the embeddings from two towers, and we use whether there is any engagement between query and tower in the past as the label of ground truth to train the query and item tower models jointly. Thus TTE is very natural to study the relations between two or multiple entity types, as we sketched in the below graph:

Why are Two-Tower Embeddings so Important?
In any modern recommendation system, there are two major steps: one being candidate retrieval (known as FPR at Uber), and the second being candidate ranking (known as SPR at Uber). In FPR, we usually need to retrieve the top hundreds or thousands of candidates among millions or hundreds of millions of candidates in a very short time such as p99 equals hundreds of milli-seconds. For example, at Uber, we need to retrieve the top several hundred most relevant stores to an eater among several million available stores, but computing the relevance score or click/order rate of several million pairs between the eater and all stores using the DL model within a very short period is not realistic, because you will make O(q *M) real-time DL inference, assuming q is the number of queries from the eaters and M is the number of stores. Instead, for this application, it is very natural and best to use a two-tower architecture, because it can easily generate two DL models (see ref and ref): one is for an eater named Query Tower, and the other is for a store named Item Tower. We use the item tower to pre-compute all store embeddings offline and then create their inverted index such as SIA₃ index at Uber for Approximate Nearest Neighbor Search (ANN). During eaters’ first page recommendations (homefeed) requests, we use the query tower to generate eater embeddings realtime, and then perform fast ANN search using the dot products between eater embeddings and store embeddings in SIA inverted index. By this way, instead of O(q *M) real-time DL inference, we only need make O(M) offline DL inference, and O(q) realtime DL inference and O(q *M) realtime dot product in ANN. Thus the computation cost will be reduced using two-tower embeddings for retrieval in the recommendation system. See below about how we use embedding in the Eats homefeed:
₃ SIA is Uber’s unified search platform, scaling across Eats, Groceries, Maps, and more.

A Closer Look: Problem and Motivation
As Uber continues to scale, the need to improve and grow our large-scale recommendation systems has increased.
Original State ≠ Scalable
The current city-wise Deep MF model used in FPR was not scalable, given the fact that Uber is serving more and more cities. The maintenance cost is also very high, because we need to run thousands of Apache Spark™ jobs on a weekly basis just for creating city-wise deep MF models. Thus it is urgent to find an alternative solution that could better scale globally. Specifically, this is broken down into two main problems.
Problem 1: Lack of efficient recommendation systems
In recommendation systems, we need to provide personalized retrieval from a large pool of stores. For example, in Eats we need to retrieve the best stores out of a few thousands in about a hundred of milli-seconds.
Problem 2: Existing technology could not scale
In addition, our existing technology doing this (Deep Matrix Factorization–DeepMF), was a bottleneck to growth as it could not scale as our business grows.
- Required thousands of city models
- Could not be reused
- Very expensive to maintain
TTE = Scalable, Extendable, and Efficient
In this case, Two-Tower Embeddings are the long-term scalable solution to this problem. Two-Tower embeddings unlock 3 major advantages that DeepMF lacked. Specifically:
- Scalable labeling: The TTE model utilizes users’ engagement such as click and order as the training label, thus it is much easier and less costly compared to classification tasks where we rely on human manual tags.
- Localization and scalable training and inference: The TTE model utilizes the simplest and localized relation (0-hop or 1-hop) in the interaction graph, thus we can pre-sample and pre-compute the entity features on disk and then fit them to the TTE model batch by batch during training and inference instead of managing (node_id -> node feature) of the whole graph in memory. The localization property makes training and inference of the TTE model more scalable and less costly compared to GNN.
- Feature extensibility: With Deep MF, we had to generate embeddings for store retrieval, in which user_id and store_id are the only features, and it is difficult to add other important information of the entity such as eater contextual features(query time, order location, etc.), numerical features (store prices, store rating, delivery distance, etc.) and NLP features (store menu, ordered dishes). However, with TTE, adding any feature to any tower is straightforward and simple to extend.

We used embeddings to solve low performance, high computing costs, and scaling blockers. We brought embeddings to Uber by building the platform capability to leverage for all use cases, starting with our champion use case, Eats Homefeed.
Here, we applied embeddings to the Eats Homefeed model to prove the value and replace DeepMF. Now we can retrieve personalized stores in about hundred of milliseconds, which was initially impossible to do, and it enables customers to quickly and easily find what they need by selecting the best store for them. Now, embeddings can be scaled, reused, and transferred beyond our initial use case.
Future Use Cases = Scalability ++
Besides The retrieval step or FPR of eats home feed described above, we identified 2 other possible use cases for TTE at Uber:
- TTE is used as final ranking layer for eats item feed (grocery recommendation)
While TTE is typically utilized for retrieval purposes, it can also serve as an effective final ranking layer in cases where other frameworks may be too costly or resource-intensive. Prior to the introduction of TTE, the Item Feed Ranking system employed non-personalized static rankings, primarily due to concerns around the potential costs and latency associated with online calls for too many item-level features. TTE as a final ranking layer is a very good solution to reduce infrastructure cost and avoid latency increases.
- TTE is used to generate transferrable features for any downstream task, including rider and place embeddings. In this case, downstream ML models will directly use embeddings generated by the TTE model as input features. Embeddings contain rich information about the entity (eater, store, item, rider, etc.) and including them in the model will greatly improve the model performance.
In the next sections, we will describe where we specifically used embeddings in SPR and FPR.
Deep Dive: The Embeddings Solution
Designing an embeddings model and the infrastructure to support it was no easy task. We needed something that supported our large amount of data, but optimized for computing cost and time. This section will cover the successful training strategy we choose, and how we simultaneously upleveled the platform for extensibility, scalability, and reusability.
Model Architecture & Training Strategy
The key metrics of retrieval tasks in the recommendation system is recall@large_N where large_N could be hundreds, thousands, or even tens of thousands. For example at Uber, we use recall@hundreds as the key metrics for Eats homefeed FPR task. In order to optimize recall@hundreds, the number of negative samples needs to be much larger than a few hundreds. On the other hand, creating so many negatives during training will blow up the training cost and time. Thus the recommended way in industry is to use “in-batch negatives.’. Nevertheless, we also need to create batches of training data smartly so that the negatives within the same batch are meaningful. So we will first discuss geometric hash and sort.
Spatial Indexing
Uber Recommendation system has a geospatial aspect to it, as the user would not order from a store far from their location. If we denote the location of eaters’ inputs query q as L(q), and the location of candidate restaurant i as L(i), then we are interested in restaurants that satisfy dh(L(q), L(i)) < δ(q,i) where dh(l1 ,l2) refers to the haversine distance between locations l1 and l2.
LogQ Correction for In-batch Negatives
The in-batch negatives technique reuses the positive sample items in a mini batch as negatives for other queries/eaters in the same batch (see research paper for reference). It is possible that the positive sample for a query also appears as a positive sample for another query in the same minibatch; this happens more often when we use geo-hash of store locations to order the training data and create mini-batch afterwards. The in-batch negatives technique attempts to use negatives in the mini-batch as an approximation of the softmax over the full vocabulary, but it is clearly biased to popular items. Therefore we need to correct this bias using logQ correction [Adaptive Importance Sampling paper, research paper], and the sampling probability in the batch is computed via multinomial distribution as Q =[1-(1-w)ᴮ] where B is the batch size and w is the item weights in the whole data. Accordingly, we shift our prediction score es/TQ = es/T – log(Q) for all pairs in M = Qitems Iᵀitems Our experience with our Global TTE Model shows that logQ correction improves recall@500 from 89% to 93%.
Modeling
Eater past activities as eater feature:
One of the most important innovations of TTE model we developed at Uber MA is that we invent a new type of activity feature, now named BOW features, in which we collect and time-decent-sort several months of previous ordered store_ids for each eater on a specific date as a proxy of eater_uuid (eater_id -> [ordered_store_1, ordered_store_2, ordered_store_3, …]). This reduces the model size by 20 times because we only have millions of stores, and this also partially solves the eater cold start problem
Layer sharing between two towers
Another very important innovation of the TTE model we developed is that we enforce neural module layer sharing between the two towers, and this is not typical in most textbook TTE models, but it turns out to be very important for the TTE model for Eats homefeed.
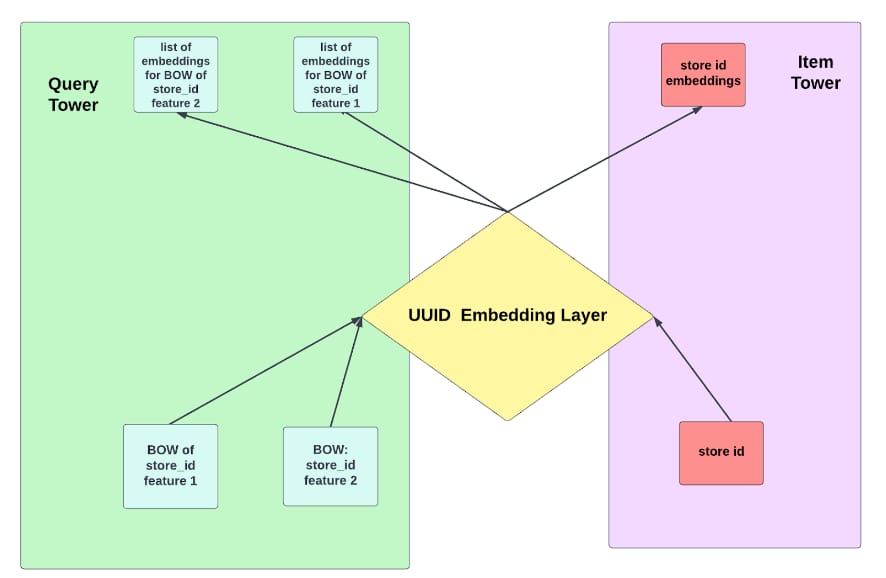
Layer sharing is not new, and it originates from pattern recognition models as early as 1989’s Zip Code Recognition Paper and popularized by AlexNet. It is also widely used in transformer models. Nevertheless, the layer sharing in the above examples are used inside each module, while in TTE we enforce layer sharing between two relatively independent tower modules. We will discuss one type of layer sharing we developed as an example: where the query tower and item tower share the same UUID Embedding Layer.
System Integration and Improvements
In addition to modeling improvements, our team took the opportunity to uplevel the platform for extensibility, scalability, and reuse. Previously the system was just a collection of custom Apache PySpark™ jobs and data processing pipelines, but now we’ve fully integrated the use case into Michelangelo. This means two- tower embeddings gain the benefits of Michelangelo across the end-to-end ML lifecycle: including data preparation, training, evaluation, deployment, and serving.
To simplify data preparation and serving, Michelangelo’s Feature Store, Palette, was enhanced with a tighter integration with Uber’s search platform. This integration means that embeddings registered in the feature store can be served both online and offline using a config-driven approach. Previously, for online serving Palette features were only accessible through Michelangelo’s prediction service and key/value store pairing.
For training and evaluation, we have leveraged and extended Michelangelo’s Canvas framework to support two-tower embeddings. With the addition of new training modules and feature encoders, other teams at Uber can now use a spec-driven approach to train and evaluate models on new use cases. By creating proper Michelangelo models, we gain the benefits of standardized production retraining workflows, deployments, and the online prediction service.

Challenges
Model Size
After conducting ablation studies, we have found that utilizing the eater_id and store_id is crucial for improving the performance of the model. These features possess high cardinality and incorporating them has led to a larger model size. However, training and deploying this large model size poses a significant challenge to our current infrastructure, demanding substantial computational resources.
Training Time
Training a large model requires a considerable amount of time–it could take several days or weeks.
Evaluation Metrics
The performance evaluation of contextual TTE models presents unique challenges, as traditional metrics like AUC or NDCG do not consider the current context of the user. To address this challenge, we have developed a comprehensive evaluation framework that assesses TTE recommendations at the session level and incorporates location and context to generate a Factorized Top K list. This list is used to generate all relevant metrics, including recall@k and business metrics, providing a robust evaluation of the TTE model’s performance. By incorporating context-specific factors, our evaluation framework ensures that the TTE model’s performance is assessed in a way that is relevant and meaningful for real-world scenarios.
Result and Takeaways
Two-Tower Embeddings is the first DL platform at Uber for FPR and Embeddings as a feature. To get here, we delivered 3 models, with significant improvements between each version.
Models and Iterations
Reusability, Scalability, and Infra Wins
By replacing the DeepMF model with our TTE model, we were able to unlock major wins on our infrastructure side. Specifically:
- Our single global model replaces thousands of city DeepMF models
- It is now scaleable to hundreds of millions eaters, millions of stores, hundreds of millions of grocery items
- We decreased model training from hundred of thousands of core-hours to thousands of core-hours per week
However, we didn’t stop there. TTE is now used in 3 production use cases, with more to come:
- FPR of Eats home feed (store recommendation)
- Final ranking layer for Eats item feed (grocery recommendation)
- To generate transferrable features for any downstream task including Eats SPR and risk
How is Uber Standing out in this Competitive Space?
The innovation is very specific to Uber’s business. For example, we focused on addressing the challenge of handling high-cardinality features, such as UUID, in building recommendation systems. The proposed bag-of-words approach and layer-sharing technique were introduced as innovative solutions to this problem, resulting in a significant reduction in model size and improved performance, as demonstrated by offline and online evaluations.
Our work contributes to the development of more efficient and effective recommendation systems, particularly in the retrieval phase. By building on existing state-of-the-art techniques, the proposed methods have the potential to inspire further research in this area, with the ultimate goal of enabling more efficient and effective recommendation systems in the future.
What’s Next?
TTE as a Platform: Adoption
One of our primary goals is to enable the widespread adoption of the TTE platform beyond just the Eats team. With this in mind, we are making significant efforts to ensure that the model is scalable and adaptable to various use cases within the company, including Map and Risk. Users can leverage the platform’s capabilities to customize and train their own TTE models, tailored to their specific needs and requirements, without the need to invest significant resources in developing the model from scratch.
By expanding the use of TTE across the organization, we can unlock significant value and enhance the performance of various processes and workflows. With its ability to process large volumes of data quickly and accurately, TTE can provide valuable insights and inform decision-making across a wide range of teams and departments.
Embeddings as a Feature
Our team is actively working to generate embeddings that are general enough to be utilized across a diverse range of applications and use cases. By developing more versatile and adaptable embeddings, we believe that we can enhance the performance of different machine learning models and unlock new opportunities for innovation and growth. Users can benefit from the embeddings we have generated by directly using them as input features for their models, thereby streamlining the development process and improving overall performance.
Acknowledgements
This major step for Machine Learning at Uber could not have been done without the many teams who contributed to it. Huge thank you to the Two-Tower Embeddings group within Uber’s Michelangelo Team, who spent countless hours developing and versioning these embeddings.
We also want to give a special thank you to our partners on the Eats, SIA, and Deep Learning teams for making this idea a reality, as well as our former colleagues who helped initiate and vouch for this idea many months earlier.
Apache®, Apache Spark™ and Spark™ are registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks.
Header Image Attribution: The “Artificial Intelligence 002” image is covered by a CC0 license and is credited to Gerd Altmann.
[ad_2]
Source link


