

[ad_1]
Introduction
Uber connects the physical and digital worlds to help make movement happen at the tap of a button. Billions of trips, deliveries, and tens of billions of financial transactions across earners, spenders, and merchants are made at Uber every quarter. LedgerStore is an immutable storage solution at Uber that provides verifiable data completeness and correctness guarantees to ensure data integrity for these transactions.
Considering that ledgers are the source of truth of any financial event or data movement at Uber, it is important to be able to look up ledgers from various access patterns via indexes. This brings in the need for trillions of indexes to index hundreds of billions of ledgers. A previous blog post discussed the background of LedgerStore and how the storage backend was re-architected. This blog covers the significance of LedgerStore indexing and its architecture, which powers trillions of indexes, with a petabyte-scale index storage footprint.
Types of Indexes
Various types of indexes need to be supported on ledgers. Let us explore them along with corresponding use cases.
Strongly consistent indexes
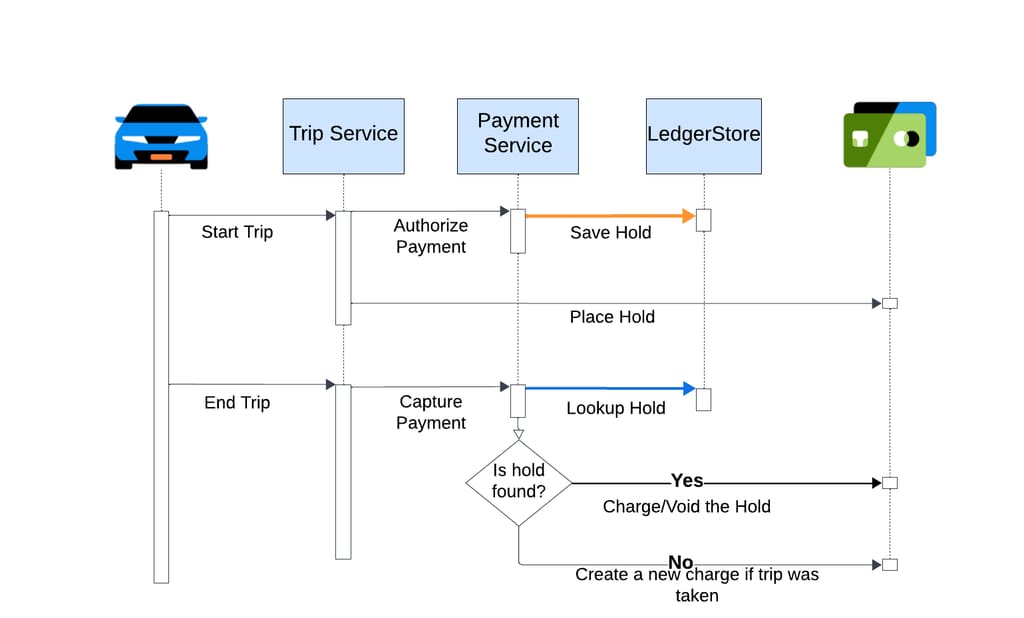
One of the use cases is handling the credit card authorization flow when a rider/eater uses Uber. At the beginning of an Uber trip, a credit card hold is placed on the rider/eater’s credit card. This hold should either be converted to a charge or voided, depending on whether the trip was taken or canceled, as shown below.

If the index serving the hold is not strongly consistent, it could take a while for the hold to be visible upon reading. A consequence of this is that a duplicate charge could be made on the user’s credit card while the original hold remains on the credit card.
Now, let’s dive into how we build strongly consistent indexes that ensure that once a record write is performed, any subsequent reads are guaranteed to see the indexes corresponding to that record.
Write Path
To build strongly consistent indexes, we use a 2-phase commit to ensure that the index is always strongly consistent with the record, as shown below.
The insert operation begins with an index intent write before the record write. These intents are committed after the record write operation if the record write succeeded and this is done asynchronously to avoid affecting end-user insert latency. If the index intent write succeeds, but the record write fails, the index intent will need to be rolled back, else it leads to an accumulation of unused intents, and that is handled during the read time, as we will see next.
It is important to note that if the index intent write fails, the whole insert operation fails since we cannot guarantee the consistency of the index with the record. Hence, strongly consistent indexes need to be considered only when the use case strongly demands it.

Read Path
There are two cases where an index can be in the intent state after the insert:
- The index intent commit operation failed in the write path OR
- If record write fails
Such intents are handled on the read path by either committing or deleting them. When a read happens on these indexes, if the index is in an intent state, the corresponding record is read. If the record is present, the index is committed, else rolled back. These operations happen asynchronously so as not to affect the end user read latency. In general, only a very small percentage of indexes end up in the intent state.

Eventually consistent indexes
Not all indexes require strong read-your-write guarantees. An example of such an index is the payment history page, wherein, a lag of a few seconds is acceptable as long as the payment appears on the page.
While strongly consistent indexes provide read-your-write guarantees, they are not suitable in certain circumstances since they trade off the following properties to achieve this guarantee:
- Higher Write Latency
Since the index intent write operation and corresponding record write has to be serial to provide a strong consistency guarantee of the index for the record - Lower Availability
A write failure of any one of the index intents implies the whole write should be failed else indexes will not be consistent with the corresponding record
Eventually, consistent indexes are the opposite in this aspect when compared to strongly consistent indexes, as they are built in the background by a separate process that is completely isolated from the online write path. Hence, they do not suffer from higher write latency or cause potential lower availability of LedgerStore service. We leverage a feature called Materialized Views from our home-grown Docstore database to generate these indexes.

Time-range indexes
Ledgers, due to their immutable nature, keep growing in size over time, thereby increasing their cost of storage. So, at Uber, we offload older ledgers in time-range batches to cheaper cold storage.
Every ledger is associated with a timestamp called a business or event timestamp. To offload ledgers to cold storage (and also for sealing the data), we need a class of indexes to query data in event time-range batches. What differentiates this index is that the data is read in deterministic time-range batches, in orders of magnitude higher than the above two index types.

Following is an example of how time-range queries are done on ledgers:
| SELECT * FROM LEDGER_TABLE WHERE LedgerTime BETWEEN 1701252000000 AND 1701253800000 |
| Ledger | LedgerTime |
| {trip started} | 10:01 am |
| {trip completed and fare adjusted} | 10:15 am |
| {post trip corrections} | 12:01 pm |
There are a few ways to model this in a distributed database. We will dive into the key differences between developing the time-range index on top of Amazon DynamoDB vs. Docstore database. Both DynamoDB and Docstore, being distributed databases, provide data modeling constructs as Partition and Sort keys. The former is meant for distributing data across partitions evenly based on its value and the latter to control the sort order of the data.
Design with DynamoDB
Dynamodb provides two ways of managing table read/write capacity. We used the provisioned mode since the traffic is not too bursty to require on-demand mode. The provisioned mode was configured with auto scaling to adjust capacity based on the traffic pattern.
As we notice from the write pattern above, the ledger times are generally correlated to the current wall clock time. Hence these values tend to be clustered around the current time. If we were to partition the data based on say G time-units granularity, all the writes in the G time-units would go to the same physical partition causing hot partitions. DynamoDB has restrictions on throughput in case of hot partitions, leading to throttling of write requests, which is not acceptable in the online write path. Assuming 1K peak Uber trips/s, even G=1 second is not a good value, since it corresponds to 1K WCU (Write Capacity Unit), which is the peak allowed QPS before throttling happens.
While it might seem like we could just make the partitioning more fine-grained, it is still not foolproof, since an increase in the traffic over time can lead to instability. Another side effect of this is the increase in cumulative reads to be performed via a scatter-gather. So, what we did in the case of DynamoDB was below:
Write-optimized temporary index table (called buffer index)
All online time-index writes go to the buffer index table. Inserted index items are partitioned into M unique buckets based on a hash modulo of the corresponding record to uniformly distribute load across partitions in the buffer index table, making it write-efficient. The value of M is chosen such that it is high enough that the amount of load per partition avoids excessive splitting. It is also chosen low enough, to limit the amount of scatter-gather to perform during reads.
Read-optimized permanent index table
The need for scatter-gather read of the buffer tables makes them not efficient for reads and since reads can happen throughout the lifecycle of a table, we would need to optimize it. This brings the need for a read-efficient permanent index table.
A permanent time-range index table is partitioned on the timestamp aligned to a certain time duration N (say 10 minutes). Indexes from the buffer tables are periodically written in batches to the permanent index table. Since the write is done in batches and in the background, any write throttling here does not affect the online traffic. Another advantage of batching is that the write traffic can be distributed across partitions, reducing the hot partitioning. The buffer index tables are deleted after offloading their indexes to the permanent index table since they are no longer needed. Reads on the permanent index tables are done in intervals of N minutes without any scatter-gather, making this table read-efficient.
Following is a depiction of the time-range index flow in case of DynamoDB. The dual table design brings in the need of state management and coordination so reads go to the correct index table as well.

Design with Docstore
The two-table design in the case of DynamoDB functions well and can handle high throughput, but introduces challenges in operations. If the temporary buffer tables are not created in time, it can lead to write failure since writes cannot be accepted, and this has caused availability issues in the past. We re-architected our index storage backend from DynamoDB to Uber’s Docstore database as part of cost efficiency. As part of this re-architecture, we also improved the time-range index design to overcome the downside of maintaining two tables, by leveraging two Docstore properties:
- Docstore is a distributed database built on top of MySQL, with a fixed number of shards assigned to a variable number of physical partitions. As the data size grows, the number of physical partitions increases and some of the existing shards are re-assigned to the new partitions, leading to a max upper limit to the number of physical partitions.
- Data in Docstore is stored in a sorted fashion of the primary key (partition + sort keys).
We maintain just one table for the time-range index, wherein the index entries are partitioned on the full timestamp value. Since the timestamp is extremely granular, there is no hot partitioning (and hence no write throttling) since most of the writes are uniformly distributed across partitions.
Reads involve a prefix scanning of each of the shards of the table up to a certain time granularity. Prefix scanning is very similar to a regular scan of the table, except the boundaries of each scan request are controlled by the application. So, in the example below, to read 30 minutes worth of data, reads could be done on a 10-minute interval starting from 2023–02-03 01:00:00 to 2023–02-03 01:10:00 and similarly repeated for the next two sub-windows. Since data is sorted on the primary key, this prefix scan with given boundaries ensures only data lying within these timestamps is read.
A scatter-gather, followed by sort merging across shards is then performed to obtain all time-range index entries in the given window, in a sorted fashion. Since the number of shards is fixed in Docstore, we can precisely determine (and bound) the number of read requests that need to be performed. The same technique is not applicable in the case of DynamoDB since the number of partitions keeps increasing over time, as the table size increases. This has significantly simplified the design and reduced the operational maintenance cost of our time-indexes.

Index lifecycle management
New indexes are defined regularly and some of the indexes could be modified as well to evolve use cases. To support that with minimal effort and also not cause any regressions, we need a mechanism to manage the index lifecycle. The following are the components of the same:
Index lifecycle state machine
This component orchestrates the life-cycle of the index, involving creating the index table, backfilling it with historical index entries, validating them for completeness, swapping the old index with the new one for read/writes, and decommissioning the old index.

Historical Index data backfill
Depending on the business use cases, new indexes need to be defined, and it is essential to backfill historical index entries so that they are complete. This component builds indexes from the historical data offloaded to the cold data storage and backfills them to the storage layer in a scalable fashion. Considering that the data download speed is higher than the data processing speed, this component is built with configurable rate-limiting and batching in a reusable way, since we can plug in the actual processing logic as a batch processor plugin.

Index validation
After indexes are backfilled, they need to be verified for completeness. This is done by an offline job that computes order independent checksums at a certain time-window granularity and compares them across the source of truth data and the index table. This step identifies any bugs in the index backfill process since even if one entry is missed, the aggregate checksum for that time window will lead to a mismatch.

Highlights
This is how we measured the success of this critical project:
- We built over 2 trillion unique indexes, and not a single data inconsistency has been detected so far, with the new architecture in production for over 6 months.
- Not a single production incident was noticed during the backfill, given how critical money movement is for Uber.
- We also moved all these indexes from DynamoDB to Docstore. So the project also resulted in technology consolidation, reducing external dependencies.
From a business impact perspective, operating LedgerStore is now very cost-effective due to reduced spend on DynamoDB. The estimated yearly savings are over $6 million per year.
Conclusion
Ledgers are the source of truth for money movement events at Uber. The robust indexing platform we have built supports accessing these sources of truth ledgers for various business use cases, and we look forward to supporting many more indexes on this platform in the future.
We would like to conclude with some key takeaways: Maintaining a petabyte-scale of indexes in an OLTP system brings in certain challenges, such as imbalanced partitioning, high read/write amplification, noisy neighbor problems, etc. So data modeling and isolation are important aspects to consider while designing these systems. Further, depending on the actual database used underneath for storage, the design methodology can be significantly different, as we see from the design contrast of time-range indexes on two different distributed databases.
Join us next week to see part two of the LedgerStore series where we chronicle a migration from DynamoDB to LedgerStore.
Acknowledgments
This project would not have been possible without collaboration from the following teams, embodying several Uber values:
- The Gulfstream team, who closely worked with the LedgerStore team in aligning on the common goals and migrating on the LedgerStore platform, a multi-year project.
- The Docstore team, for evolving Docstore to meet the massive scale requirements of LedgerStore’s indexes.
- The LedgerStore team for leading, building, and driving the adoption of ledger indexes at large scale.
Amazon Web Services, AWS, the Powered by AWS logo, and Amazon DynamoDB are trademarks of Amazon.com, Inc. or its affiliates.
[ad_2]
Source link

