

[ad_1]
Introduction
A few years ago, we started tackling flaky tests in an effort to stabilize CI experience across our monorepos. The project first debuted in our Java monorepo and received good results in driving down frictions in developers’ workflow. However, as we evolved our CI infrastructure and started onboarding it to our largest repository with the most users, Go Monorepo, the stop-gap solution became increasingly challenging to scale to the scope.
Visibility
The legacy service had an analyzer built-in, which categorizes tests based on a window of historical test runs. However, most of the time it works in a sandbox with little visibility into details, like what history it has examined for a test, what the reason was behind a decision, or additional information about a test. Thus, often some tests were miscategorized but we didn’t know why and had to manually recategorize.
Customization
It also has little extensibility of supporting different strategies to categorize tests. It only supports the sliding window strategy to categorize tests. The legacy test model is specifically tailored to Java, assuming inputs like test suites, parameters, annotations, etc., which are not always available in other languages.
Complexity
The “serial” and “parallel” concepts add additional logic on each monorepo’s CI side to respond differently. Also, because it encapsulates many scenarios–categorize, transition, recover in CI, notifications, etc. – complexity greatly increases when it needs to be both generic enough to accommodate each repo and effective enough to not miss any flakiness.
Actionability
At the time we hadn’t reached consensus as to how ownership was defined across repositories. So we ended up with a lot of flaky tests being ignored in CI, but with no accountable tracking.
The Big Picture
At Uber, we run extensive sets of tests in our CI pipelines at various development stages. On a typical day, we validate 2,500+ diffs (code changes, a.k.a. pull requests) per day and run over 10k+ tests per diff on average. Our ultimate goal is to make sure developers have confidence in the main branch by keeping it always green. Flaky tests undermine the reliability of our CI pipeline, leading to chaos in developer experience–one bug becomes more bugs.
Furthermore, with our SubmitQueue speculation architecture, failing a revision can have cascading effects invalidating other revisions in the queue and causing blockage. This gets worse when there’s cross-cutting change that affects the entire repository and triggers all tests, which will be a nightmare to land a code change. This may lead to developers constantly retrying their builds until the build becomes green, wasting engineering hours and CI resources.
It became an urgent need to develop an effective, scalable, and configurable system that can be easily adopted and responsive to thousands of tests’ state changes.
Introducing Testopedia
We need to obtain visibility over all the tests that we run in Uber to validate users’ changes. This visibility includes reliability characteristics (i.e., flakiness control) and performance characteristics (i.e., latency control). Thus we need a centralized system to track all our tests and provide enough context to CI or any other consumers to make decisions with regard to these tests. We isolated these responsibilities to a standalone service, Testopedia.
Design Overview
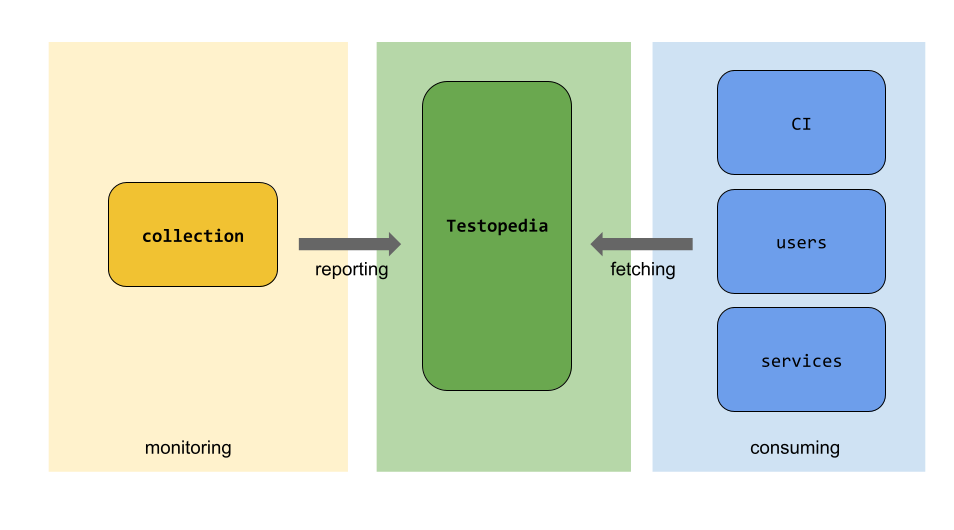
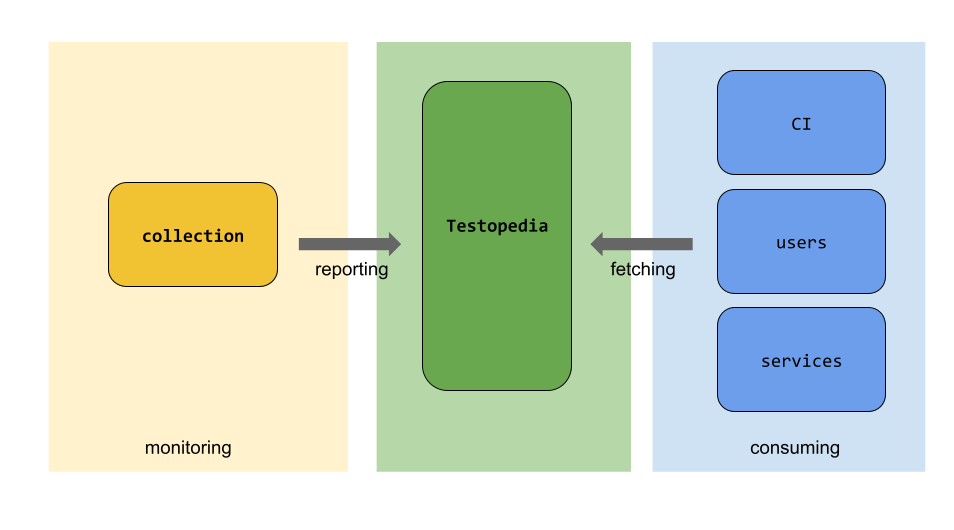
Testopedia sits in our CI infrastructure between reporting and consumers, as below:
What it does
Instead of having Testopedia handle all aspects of flaky tests, we decided to make it language/repo-agnostic. This means the service doesn’t care what kind of test it is, whether it’s a test suite or test case, how the name is formatted, how it’s reported, how it’s handled in CI, etc. It simply operates on “test entity,” which is the minimal fundamental unit in the system and is uniquely identified by a “fully qualified name” (FQN). Additionally we introduced a grouping concept for the FQNs–realm, which encapsulates all tests under a specific usage domain, such as Golang unit tests, Java unit tests, Docker integration tests, etc. Realms are owned by specific platform teams and each team can construct FQN to their own liking.
Next, on a high level, we assign 3 function domains to the service:
Read
- Retrieve individual test’s stats, including flakiness state, reliability, staleness, aggregated execution time, historical run stats and other metadata if any.
- Retrieve a groups tests’ stats, a list of the above.
- Retrieve the state changes for a test.
Write
- Upload the test running results to the system.
- It could be in a form of file or streaming but need to follow a predefined schema.
- Administrative operations to disable/enable/delete certain tests in the system.
Notify
- Whenever a test becomes unhealthy, we need to trigger a JIRA ticket with deadline assigning to the owning team.
How it works
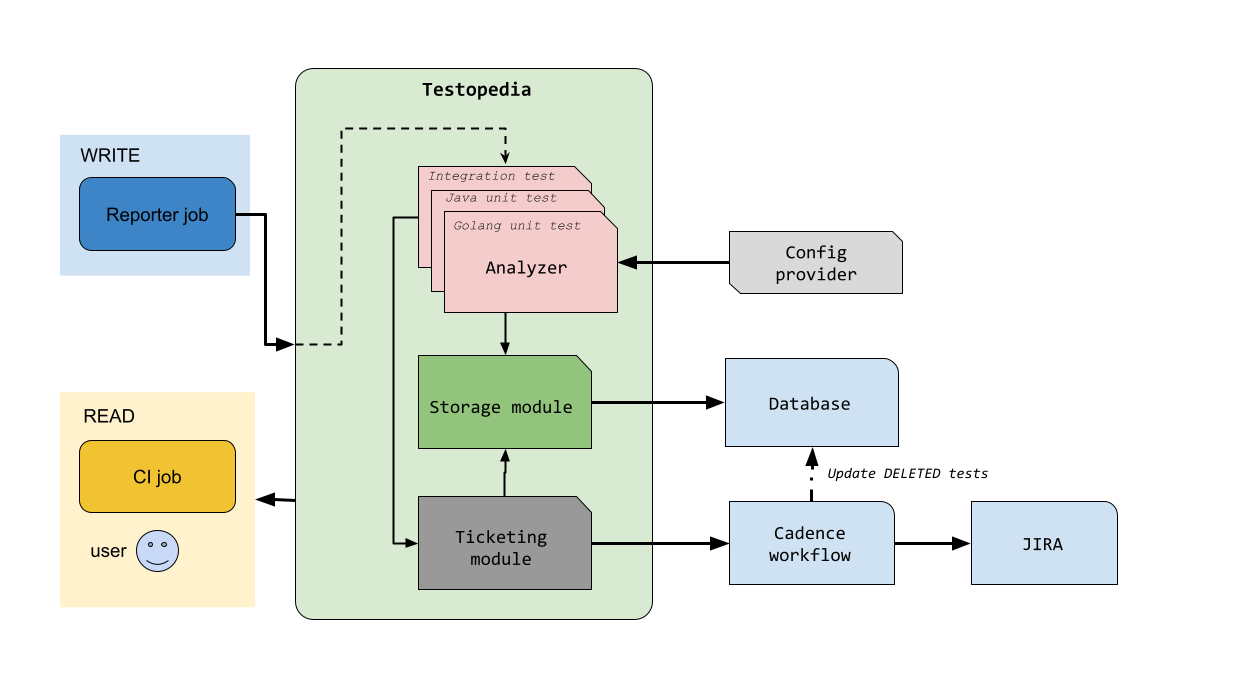
Testopedia works over historical data to infer if a test is healthy or not. But rather than fixating on the periodic job, Testopedia accepts all test data sources, regardless of whether it’s from periodic or regular validation jobs. Each report will be tagged with their source accordingly. Then every analyzer will have access to all this information and will take different strategies to respond to them (more on “analyzer” later).
After analyzer is done with running analysis on a test, a result is materialized into storage for querying later and depending on the result, a ticket will be filed to the test’s owning team, following the realm’s grouping rule (more about this in Notification).
Note that from analyzer to ticketing, every strategy is extensible and configurable outside of Testopedia’s core logic, granting maximum customizability to realm owners.
Implementation Highlights
Fully Qualified Name (FQN)
The key part of Testopedia design is the ability to address every test we execute at Uber with a unique string identifier named Fully Qualified Name, or short FQN. The system only needs to focus on analysis and bookkeeping of FQNs and leave handling implementation to each platform of their own, without having to know any details of each testing framework.
All tests are grouped into realms. Realm name starts the FQN string and represents a broader domain which tests belong to. An example of a realm is “golang.unit_test” or “android.integration_test”.
As an example of a valid FQN under the “Golang unit test” realm, we can put together a string that looks like this:

The entire FQN can be customized to whatever format by the realm owner. It is typical to model the identifier after the file system structure where the test code is located. Not surprisingly, FQN looks very much like an Internet URL as it serves the similar purpose of identifying the resource uniquely.
Finite State Machine (FSM) model
Testopedia leverages a robust finite state machine implementation to capture and record the transactional states of tests. A test entity is permitted to transact between the following states: new, stable, unstable, disabled, and deleted.
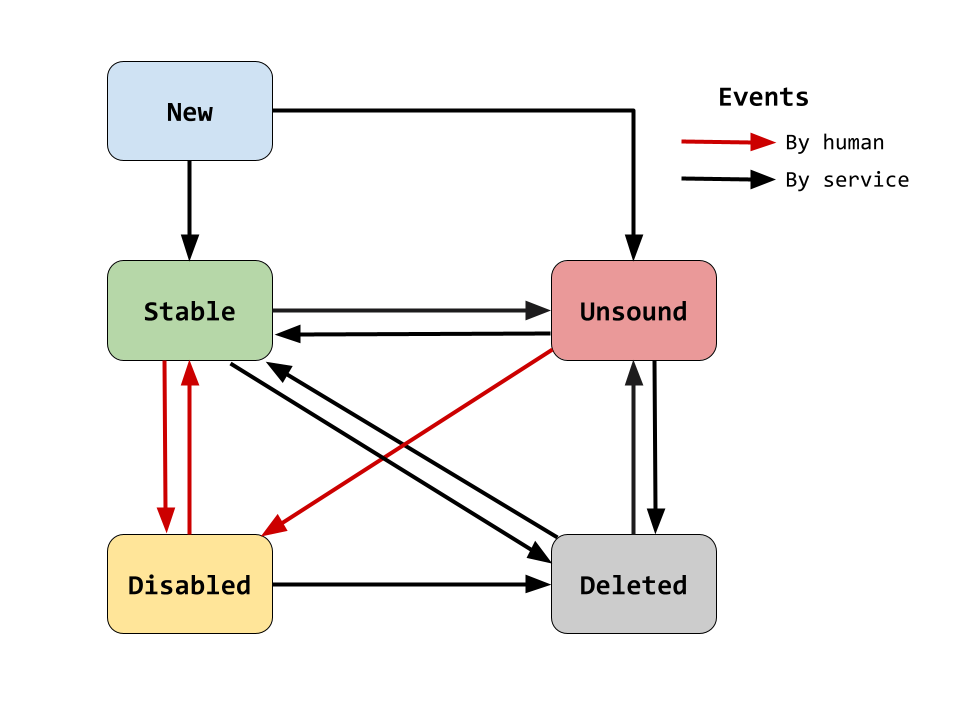
Each state can customize its own enter and exit action. For example, when FSM enters an unstable state, an action is fired to file a JIRA ticket; when FSM enters a stable or deleted state, the associated JIRA ticket is closed.
Sticking with FSM design, we were able to save on boilerplate code which we otherwise would have to write and support.
Scalability
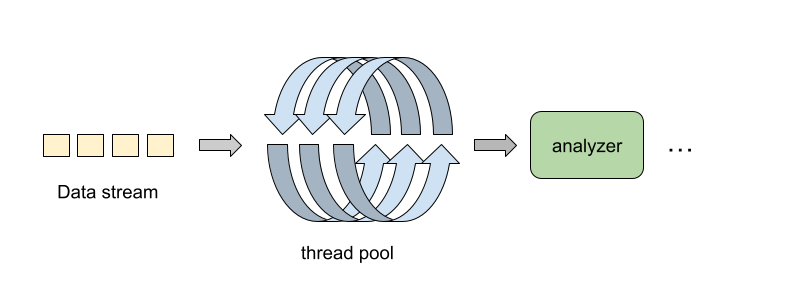
In order to maximize efficiency, we opted to implement the import API using gRPC streaming instead of asking users to upload large chunks of data. On top of this, we also implemented thread pooling to consume the data stream. This not only allows for more manageable data transmission over long-lived connections, but also ensures better resource utilization through parallel processing on both client and server sides.
Furthermore, we designed the backend database with scalability in mind, by allowing flexible partitioning, so that more complex read scenarios are supported (more about this in the next section).
Cone queries and dynamic partitioning
Because flaky tests will be heavily queried by CI, it’s a natural requirement to support query by prefix, such as “golang.unit/src/uber.com/infrastructure/*”, which in the Testopedia API model is called a cone query.
In a very common Monorepo setup, CI builds are executed as multiple parallel jobs, divided by similar path prefixes. Thus each CI job is only interested to know about flaky tests under a specific repository folder, but not all of them.
As we track millions of tests, iterating through the entire database to find a prefix match is not performant. We naturally think of sharding, however, we don’t want to just shard on a fixed length of prefix, because the cone query can come with any length, such as “golang.unit/a/b/c/*”, “golang.unit/a/b/*”, “golang.unit/a/*”, etc. To do this efficiently, we implemented a flexible bucketing algorithm:
WRITE:
- When a new FQN arrives in the system, say “golang.unit/a/b/c/d:test”,
- First we randomly generate an integer bucket ID for it, say 10
- Then we strip the realm and identify the first 3 prefixes:
- [a/b/c, a/b, a]
- (3 here is a configurable value for depth, just an example)
- Next we store the bucket ID along with all prefixes in a separate table by appending it:
| Prefix table | Before inserting (existing bucket IDs created by other FQN) | After inserting |
| a/b/c | [] | [10] |
| a/b | [2] | [2, 10] |
| a | [2, 3] | [2, 3, 10] |
- Finally we store the bucket ID along with the FQN itself in a separate FQN table that’s partitioned by bucket ID
# FQN table
golang.unit/a/b/c/d:test, 10
- Potentially different buckets can persist into different database servers, making the setup almost infinitely scalable
READ:
- When we issue a cone query, say “golang.unit/a/b/*”
- We first locate the realm “golang.unit” then locate the prefix “a/b”
- Then we refer the the partitions table and get all the bucket IDs [2, 10]
- Then we can quickly look up FQN table for records with bucket ID 2 or 10; the read should be very fast since it’s partition key; we can also execute such lookups in parallel
- Finally we iterate through selected records and filter our those that meet query requirement
Note that the depth of path for which we keep track of bucket IDs is a predefined value in config. So that for longer queries, such as “golang.unit/a/b/c/d/e/*”, we stop at the maximum depth “a/b/c” and read all records with bucket ID 10.
This way we can significantly reduce the number of records to read from DB. Furthermore, each realm can configure their own depth and number of buckets according to their query patterns. Because bucket IDs are dynamically generated rather than dependent on static input, it helps with distributing the data more evenly across buckets, regardless of their physical location in the repository.
This design realizes an important benefit: a very traditional relational database, like MySQL in multi-sharded configuration, can be used to power the storage backend and execute complex cone queries with sub-second latency.
Data-agnostic ingestion
Currently Uber hosts a monorepo for each primary language, each with its own dedicated CI pipeline. Our vision for Testopedia is to create a language-agnostic platform that can benefit all CI pipelines. Each language repository owns a realm, defines their own FQN format, and is responsible to initiate monitoring jobs, which sends streams of test history data to Testopedia. The data must follow a predefined universal schema, which is the only protocol between reporter and the service.
Consumers are free to determine how to consume from Testopedia. This approach effectively decouples the system’s logic from any language-specific concepts, such as test suites in Java or subtests in Go, ensuring adaptability regardless of the format. As a result, developers can seamlessly integrate this service into their CI infrastructure.
Configurable analyzers
The Analysis module in Testopedia is also highly configurable. It provides a common interface and the owner of each realm can either use our default linear analyzer or submit their own implementation that’s tailored to their specific requirements of detection.
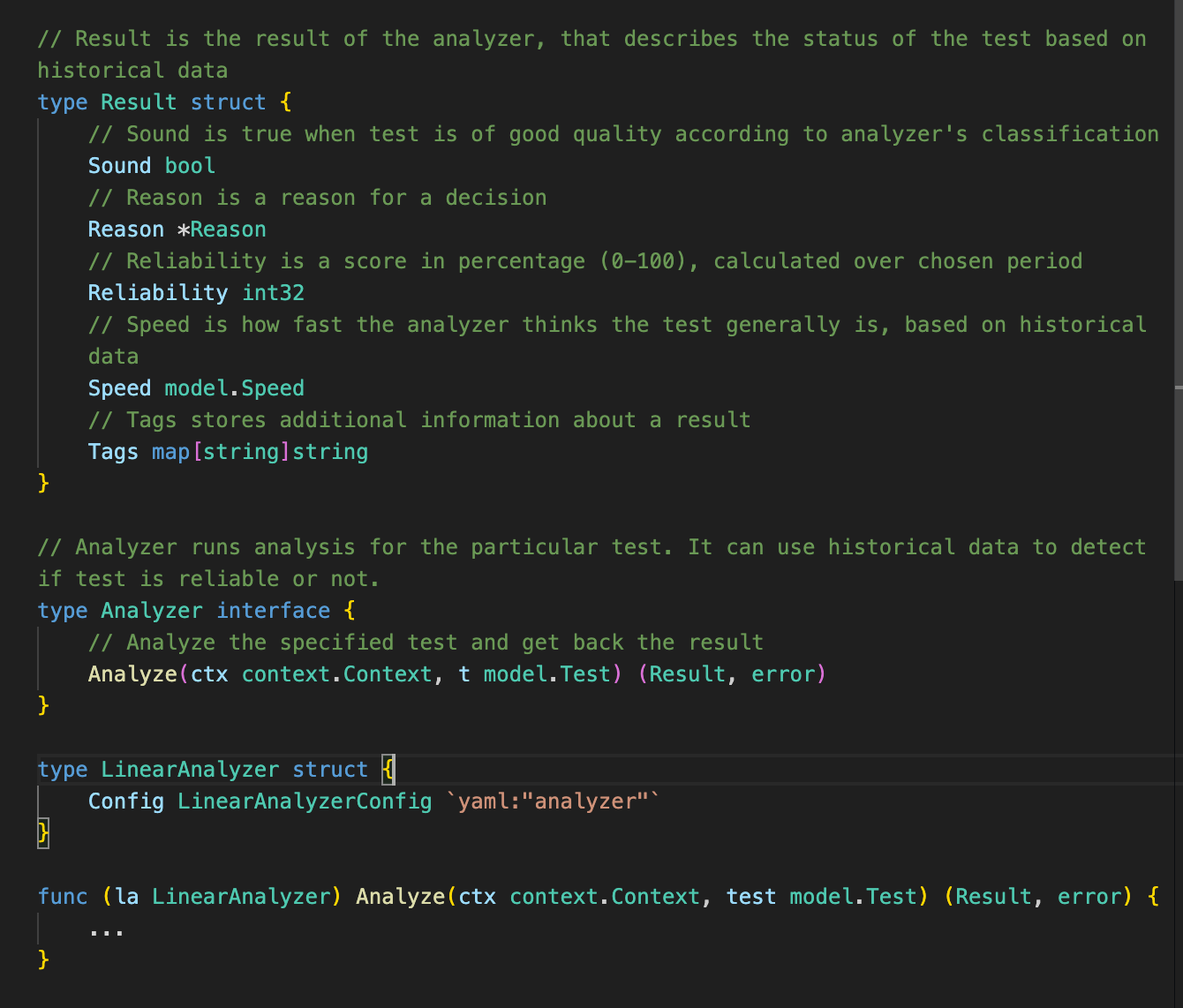
Furthermore, users can reuse any analyzer implementations and define rules based on results, lookback window, thresholds, states patterns to identify flaky tests efficiently specific to their own realm (more about this in the next section).
This customization strikes the right balance between minimizing false positives and capturing genuine flaky tests.
Configurable ticketing system and storage
We also modularized the system to accommodate our ever-evolving infrastructure at Uber. So that users can hook up other scrum solutions such as JIRA, Phabricator, and various DB solutions for storing the tests and histories. More on this in the “Managing Flaky Tests” section.
Visibility and usage
One of the key features of Testopedia is its ability to offer comprehensive visibility into test history. Every state transition, along with associated job and metadata is recorded, creating a transparent audit trail for test owners to debug and investigate when and where the flakiness happens, what the error is, how frequent it is, at which commit, etc. Furthermore, we also build CLI and web UI on top of it, so that everyone can easily inspect their tests.
Analyzing Flaky Tests
While identifying flakiness in a monorepo setup, we want to be both accurate enough that we catch them on time thus preventing their blast radius from expanding to other engineers’ workflows, and tolerant enough that we don’t ignore them all and still have sufficient coverage guard in our code.
In the Go Monorepo we execute all the tests under the main branch periodically with limited resources. This way we can expose more flakiness in tests that are resource-intensive. Then we send the results as-is to Testopedia, which runs them through a linear analyzer to determine the state of the test based on their histories.
If a test fails once in the last X window of runs, it is classified as unstable. On the other hand, because resources on the machine are compromised on purpose, some tests might tend to timeout more often, but it’s not their fault. In this case, the analyzer also grants each test a threshold M to timeout. For a test to be classified as stable, the test must pass N times consecutively. We also recognize that a test can become consistently failing due to a bug and mark it accordingly, so users will be notified of this change later.
Additionally, we also send results data from our regular landing CI pipeline. Because we have retry logic there, if a test fails for the first time but passes an identical retry, we know that this test is flaky. We label the import stream differently and make analyzer Testopedia aware, so they don’t interfere with each other.
With all of the above described, we would have a config that looks like this:
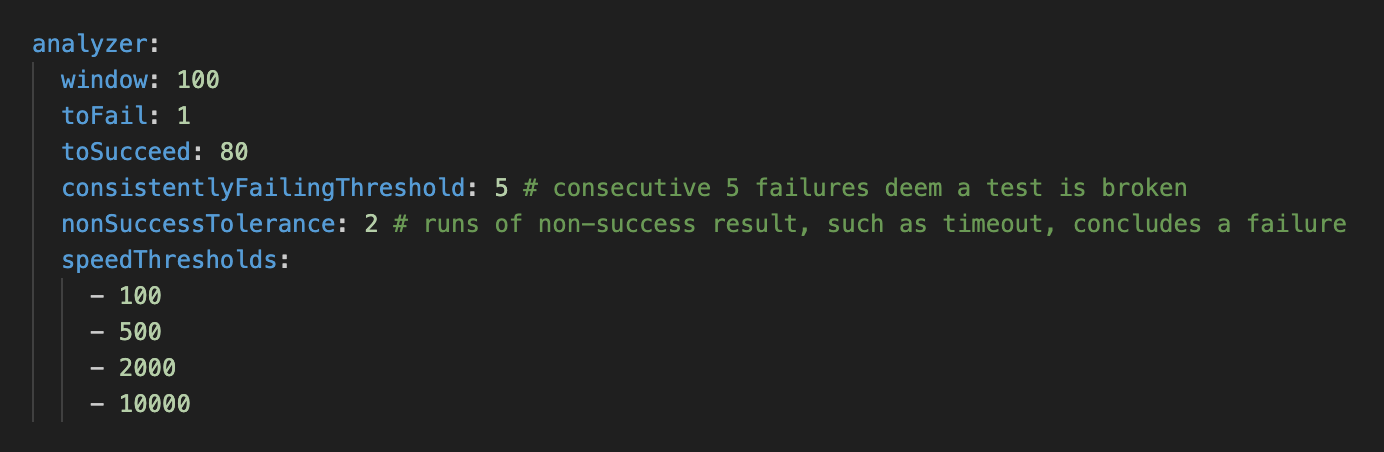
As aforementioned, all these behaviors of analyzers are highly extensible. For example, integration tests may be more prone to timeout and flakiness. The standard linear analyzer is not a good fit. In this case, a different percentage-based analyzer is implemented for them. It categorizes a test as flaky if the failure percentage in the last N runs exceeds a certain threshold. Other analyzers can also be easily plugged in. These might include analyzers designed to inspect specific error messages, those sensitive to timeouts, or those prioritizing the detection of failure trends, among others.
Managing Flaky Tests
After finding those flaky tests, we need to treat them and notify the owning teams.
Treating Flaky Tests
In a Monorepo setup, landing large diffs that affect many libraries and their tests can be very challenging, and worse, when they have flaky tests. One flaky failure that’s not caused by the diff itself could result in a full rebuild of the entire Job.
Our general guidance is to avoid running flaky tests in CI. However, issues quickly arise when the engineer tries to fix a flaky test and submits the diff. If it’s still ignored in CI, then we have no idea whether that fix works or not. Or even worse, it may completely break the test, but because CI doesn’t validate it, we never know it’s broken.
Thus, we have implemented several strategies around this:
- Tests that are specifically marked “critical” will be run on CI jobs regardless of flakiness
- Engineers can specifically added tags or keywords in diffs to opt out of that behavior
- Other flaky tests, such as integration tests, are run in non-blocking mode as FYI only
Reducing Impact of Flaky Tests
Strategy to skip flaky tests during CI phase is implemented by each realm owner. For example, Golang and Java may have very different test runner patterns, and hence use different test filter mechanisms.
In the Go Monorepo, for example, we have different methods to skip test cases and test targets. To skip test targets, we exclude running flaky test targets directly in CI, but still ensure the target is buildable. What if the target only contains certain flaky test cases and the other test cases are still useful? We implemented a feature in rules_go to skip test cases by the Go 1.20 -skip tests flag and parsing TESTBRIDGET_TEST_ONLY environment variable. This way, the information about flaky tests is isolated from the input of the Bazel rule, and the tests cache can stay stable regardless of flakiness.
Accountability
Now we have found some flaky tests and acted accordingly in CI. What’s next?
We need to notify test authors of such findings and encourage them to fix the tests as soon as possible. We can do this by immediately calling ticketing modules such as JIRA, Slack, etc. However, there are thousands of tests in even the smallest realm at Uber, and obviously we can’t afford the latency and cost of waiting for an external system to respond or file tickets for every single one. Thus we designed an asynchronous system within Testopedia that can file tickets based on grouping rules.
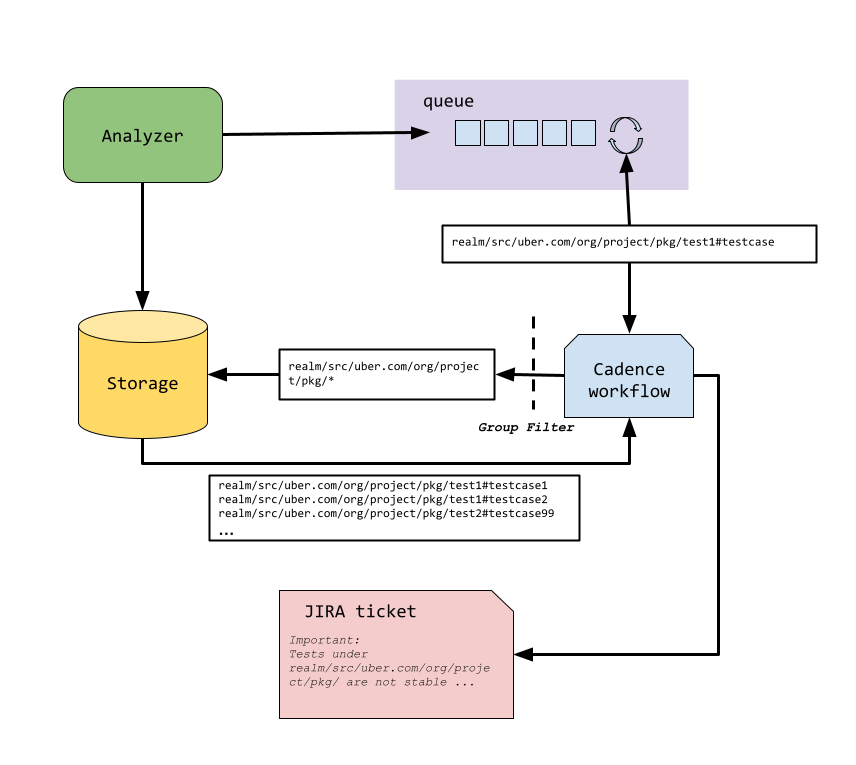
When a test is determined to be unhealthy by the analyzer, in addition to being updated in the database, it’s also inserted into a queue of messages. The queue is then poked by a cadence workflow to examine these tests again and call into JIRA to file tickets to the owning team. A Bazel test target can have multiple test cases, we track each of them as an FQN, but we only want to file one ticket per group of similar tests to reduce noise. Thus we came up with a grouping concept that put all unhealthy FQNs in one ticket per their group–either by build target or by regex.
We also made the entire module customizable, that a user can customize the grouping rule, ticket types, priority, and even the ticket description template. A typical task config looks like this:
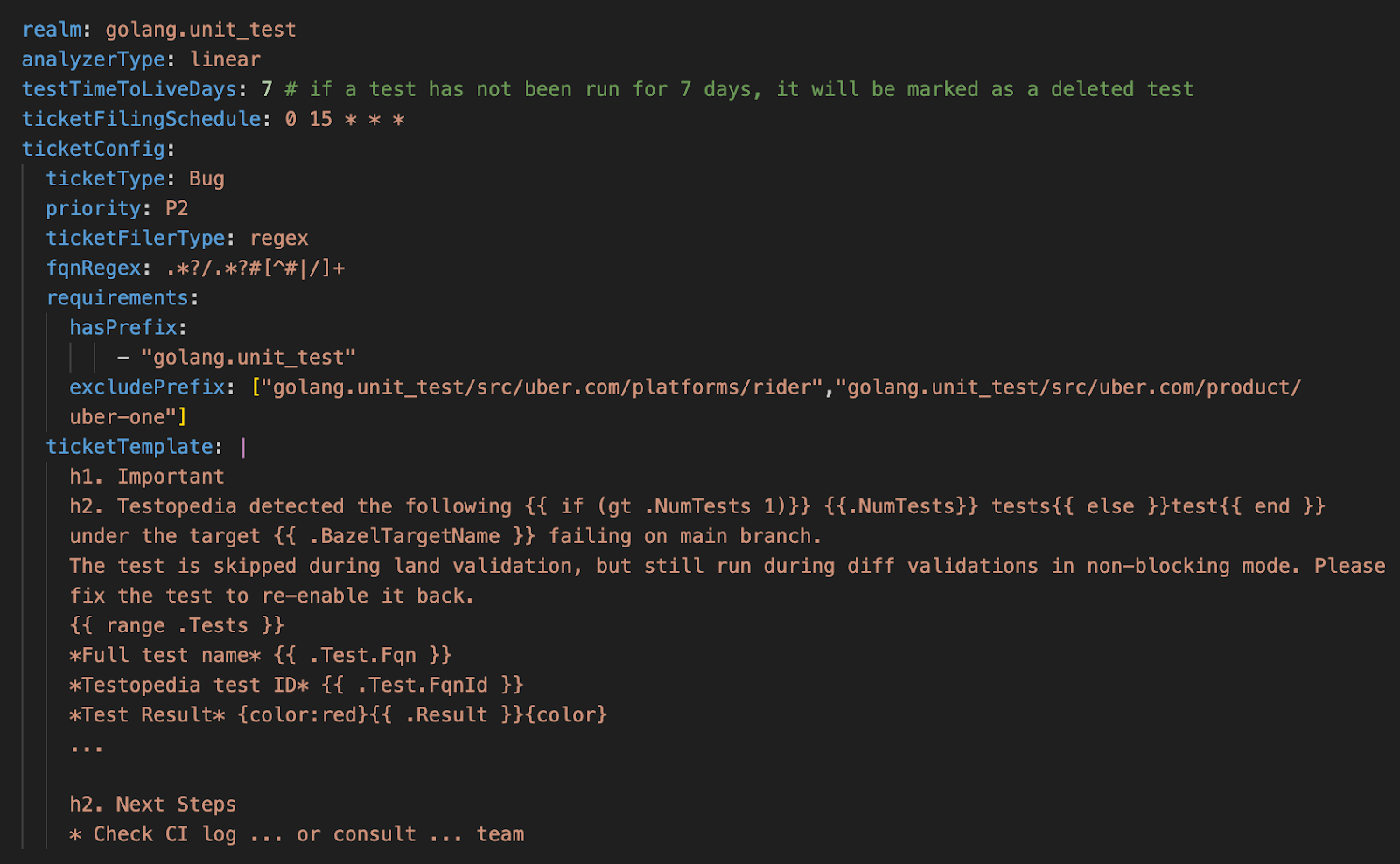
This way teams will have different test structures and define their own notification strategy tailored to their users’ experience.
Future Plans
Uber is actively developing various LLMs to improve our developer experience. We envision incorporating these cutting-edge technologies in to the system in the future:
Integrate GenAI for automated flaky tests resolution
After an FQN is imported and analyzed, with access to all its historical data and other tests failing patterns, we could use GenAI to auto-generate fixes for that test. We are exploring GenAI integrations built in-house at Uber to help centrally drive down the number of unsound tests in our Monorepos with minimal input from test owners.
More granular failure categorization and sub-categorization
The current FSM model provides generic buckets of categorization, however, not all test failures are the same. Sub-categorizations are done explicitly at the realm level. By leveraging AI to analyze failure patterns, we could automatically categorize test failures into more specific subgroups based on factors such as error logs and types, test environments, or code context of failure. This enhanced classification system would enable us to conduct more efficient troubleshooting and resolutions.
Conclusion
Now that all of the major Monorepos at Uber are onboarded to Testopedia, and along with numerous optimizations in both the internal algorithm and infrastructure components, it has been more stable than ever. In the Go Monorepo, we are steadily detecting around 1000 flaky tests out of 600K in total and 1K/350K in Java. We also observed significant improvement in reliability of CI and huge reduction of retries. Nagging developers with Jira tickets containing the right information helped tremendously to reverse the trend of an ever-growing number of unstable tests.
[ad_2]
Source link

