

[ad_1]
Introduction
The Developer Platform team at Uber is consistently developing new and innovative ideas to enhance the developer’s experience and strengthen the quality of our apps. Quality and testing go hand in hand, and in 2023 we took on a new and exciting challenge to change how we test our mobile applications, with a focus on machine learning (ML). Specifically, we are training models to test our applications just like real humans would.
Mobile testing remains an unresolved challenge, especially at our scale, encompassing thousands of developers and over 3,000 simultaneous experiments. Manual testing is usually carried out, but with high overhead, it cannot be done extensively for every minor code alteration. While test scripts can offer better scalability, they are also not immune to frequent disruptions caused by minor updates, such as new pop-ups and changes in buttons. All of these changes, no matter how minor, require recurring manual updates to the test scripts. Consequently, engineers working on this invest 30–40% of their time on maintenance. Furthermore, the substantial maintenance costs of these tests significantly hinder their adaptability and reusability across diverse cities and languages (imagine having to hire manual testers or mobile engineers for the 50+ languages that we operate in!), which makes it really difficult for us to efficiently scale testing and ensure Uber operates with high quality globally.
To solve these problems, we created DragonCrawl, a system that uses large language models (LLMs) to execute mobile tests with the intuition of a human. It decides what actions to take based on the screen it sees and independently adapts to UI changes, just like a real human would.
Of course, new innovations also come with new bugs, challenges, and setbacks, but it was worth it. We did not give up on our mission to bring code-free testing to the Uber apps, and towards the end of 2023, we launched DragonCrawl. Since then, we have been testing some of our most important flows with high stability, across different cities and languages, and without having to maintain them. Scaling mobile testing and ensuring quality across so many languages and cities went from humanly impossible, to possible with the help of DragonCrawl. In the three months since launching DragonCrawl, we blocked ten high-priority bugs from impacting customers while saving thousands of developer hours and reducing test maintenance costs.
This blog will cover a quick introduction to large language models, deep dive into our architecture, challenges, and results. We will close by touching a little on what is in store for DragonCrawl.
What Are Large Language Models?
Large language models (LLMs) are a transformative development in the field of artificial intelligence, specifically within natural language processing (NLP). Essentially, LLMs are advanced models designed to understand, interpret, generate, and engage with human language in a way that is both meaningful and contextually relevant. These models are trained on vast datasets consisting of text from a wide array of sources, enabling them to learn the nuances, idioms, and syntax of natural language. One of the most critical aspects of LLMs is their ability to generate coherent and contextually relevant text based on input prompts. This capability is not limited to simple text generation; it extends to complex tasks like answering questions, translating languages, summarizing documents, and even creating content like poems or code. The underlying technology of LLMs typically involves neural network architectures, such as transformers, which are adept at handling sequential data and can capture long-range dependencies in text. This makes them particularly effective for tasks that require an understanding of context over longer stretches of text. Modern large language models are trained on many languages, which means that we can use them and get reasonable outputs in other languages.
Why Did We Choose Large Language Models for Mobile Testing?
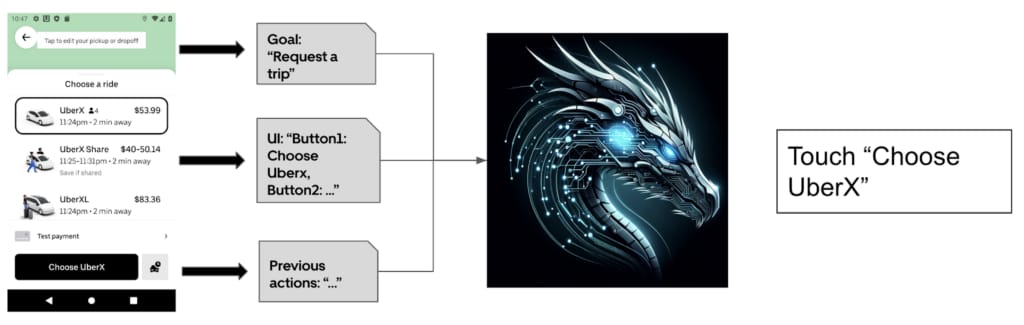
We realized that we could formulate mobile testing as a language generation problem. At the end of the day, mobile tests are sequences of steps, which may encounter obstacles and/or course corrections due to changes in apps, devices, etc. To successfully get through those obstacles and complete a test, we need context and goals, and the simplest way for us to provide these to an automated system is through natural language. We provide DragonCrawl with the text representation of the current screen, along with the goals of the test we want to execute, and then we ask it what we should do. Given the context, it chooses what UI element to interact with, and how to interact with it. And because these models have been pre-trained and proven resilient in languages besides English, we can ask DragonCrawl these questions with text in other languages.

Modeling
MPNet, or “Masked and Permuted Pre-training for Language Understanding,” is an advanced approach in natural language processing that combines masking and permuting strategies in pre-training language models. It works by masking some words and altering the order of others in the input text, enabling the model to learn not only the prediction of masked words, but also the broader context and syntax of the language. This dual-task approach allows MPNet to gain a deeper understanding of language semantics, surpassing traditional models that focus solely on masking or permutation. Once trained on large datasets, MPNet can be fine-tuned for a variety of NLP tasks, offering enhanced performance in understanding and generating language due to its comprehensive grasp of both word-level and sentence-level contexts.
Evaluation
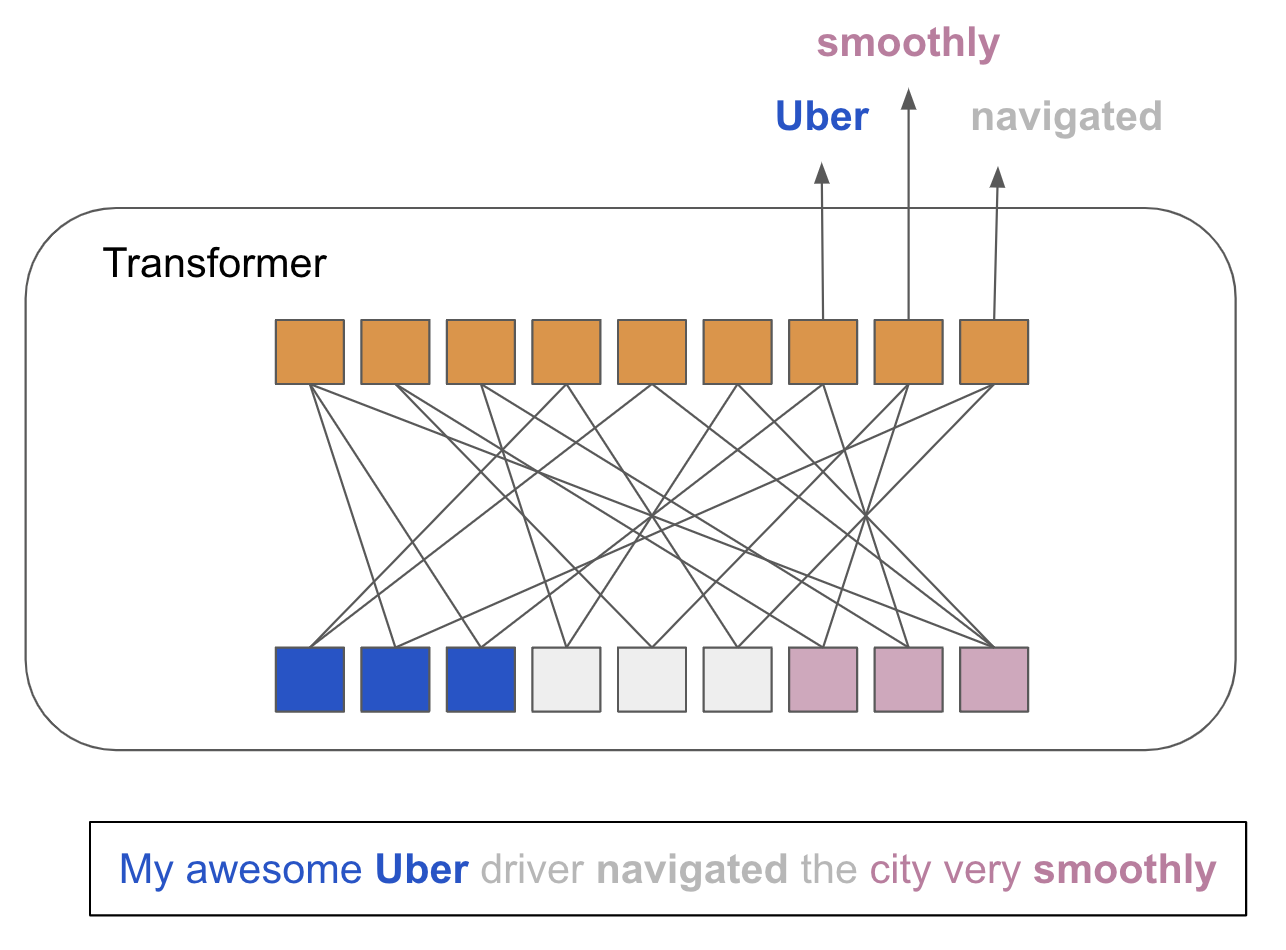
In the vast and intricate landscape of language, words are not mere strings of letters; they are rich with meaning, context, and subtle nuances and that is where embeddings come into play. Embeddings are like multi-dimensional maps, where each word finds its unique place, not just based on its own identity but also in relation to the words around it. By obtaining high-quality embeddings, we ensure that our model perceives language not as a random assortment of words, but as a coherent, interconnected fabric of ideas and meanings.
We framed the evaluation as a retrieval task because we ultimately want DragonCrawl to mimic the way humans retrieve information and make decisions. Just like how we put some effort when choosing the right book in a library, DragonCrawl makes an effort to choose the right action to take to accomplish its goals. The precision@N metric, akin to finding the right book when you can only take a handful of books home, shows us the model’s ability to not just retrieve, but to pinpoint the best option in a sea of possibilities. By measuring and improving embedding quality through precision@N, we ensure that DragonCrawl does not just understand language, but comprehends it with a discerning, almost human-like acuity.
To choose the right model for DragonCrawl, we tuned and evaluated several models. The table below summarizes our findings:
| Precision@1 | Precision@2 | Precision@3 | Parameters | Embedding size | |
| MPNet (base) | 0.9723 | 0.9623 | 0.9423 | 110M | 768 |
| MPNet (large) | 0.9726 | 0.9527 | 0.9441 | 340M | 768 |
| T5 | 0.97 | 0.9547 | 0.9338 | 11B | 3584 |
| RoBERTa | 0.9689 | 0.9512 | 0.9464 | 82M | 768 |
| T5 (not tuned) | 0.9231 | 0.9213 | 0.9213 | 11B | 3584 |
As can be seen, embedding quality is high across all models, but latency varies significantly. The fastest model turned out to be the base MPNet, with ~110M parameters (which technically makes it a small/medium language model). Furthermore, its embedding size is 768 dimensions, which would make it less expensive for other downstream systems to use our embeddings in the future.
On a different note, given those numbers, one could argue that we did not even need tuning, but that is not what we chose. T5-11b not tuned gave us good precision@1, 2, and 3, but given the frequency with which we plan to use this model, and the variability in the data because the Uber app changes constantly, we would quickly suffer from those extra points not provided by a model not customized by us.
Challenges
There were several challenges we needed to overcome during development. Some of them were specific to Uber, and some of them were related to the weaknesses of large language models.
An issue we faced early on while making DragonCrawl’s request and completion of trip flows was setting up the GPS location of DragonCrawl’s (fake) riders and drivers. Uber’s matching algorithms, which are in charge of connecting riders to drivers, are very complex and are built for scale, and even take into account variables such as time of day, current traffic conditions, future demand, etc. However, when testing with DragonCrawl, there would only be 1 rider and 1 driver in a particular city at any given time, which is not what Uber’s backend expects. Thus, there were times when riders and drivers would not be matched, even if they were right next to each other. To solve this problem, we had to tune the GPS locations of both riders and drivers, so that we would get favorable results. This is very specific to Uber and/or ride-hailing and food delivery.
Adversarial Cases
When testing Uber’s trip flow, in some cities, we saw DragonCrawl do some quirky things. In some cities, instead of requesting regular trips, it requested scheduled trips. What puzzled us the most, after debugging our artifacts carefully, is that DragonCrawl actually had all the conditions to make the right choice (i.e., touch on “Choose UberX”), but instead, it would choose a scheduled ride. Then, it would go through the UI to open a calendar and choose the date and time of the scheduled ride, which is impressive–but we digress.
The example above is called an adversarial case. The concept of adversarial cases or adversarial samples was popularized a few years ago when researchers saw that it is possible to confuse a model in cases that should not be confusing at all. Let’s take a look at the image below. In the image below, we show how, if we add a little bit of noise to an image of a panda, which results in pretty much the same panda, we can confuse a machine-learning model, to the point that it would think it is a gibbon (but we all know pandas do not look like gibbons).
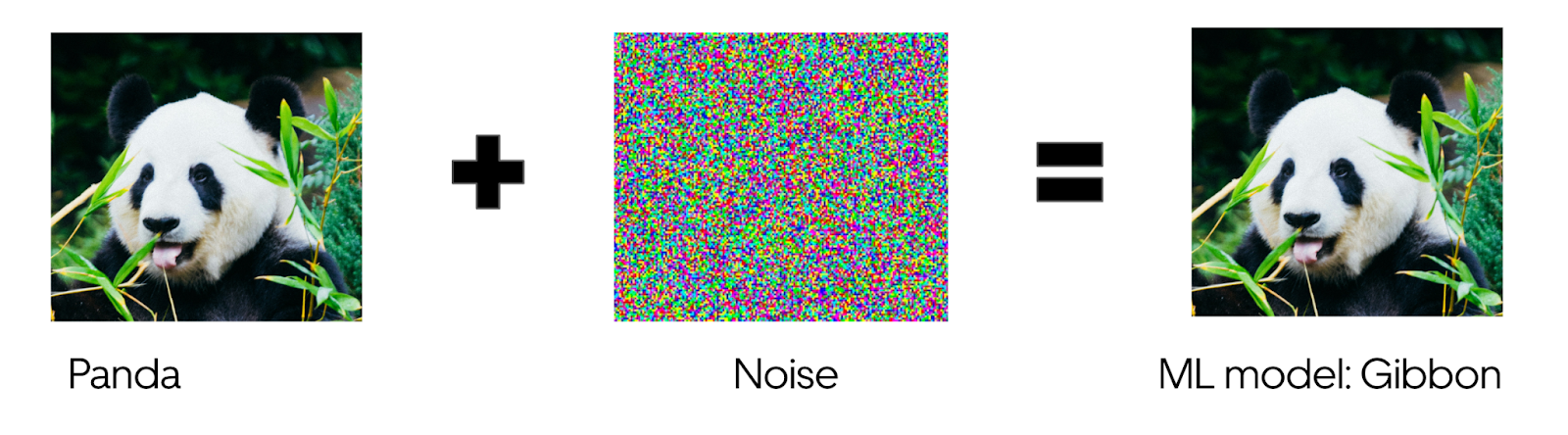
While it is impossible to fully rid a model of weaknesses to adversarial cases, we plan to do adversarial training and validation to reduce the risk.
Steering DragonCrawl to More Optimal Paths
In our offline tests of Uber’s trip flow, we saw that DragonCrawl can always request or complete a trip, but sometimes it would take too long to do so. There were times when a new pop-up would make DragonCrawl add another passenger/book a trip for someone else, which would then load several screens with options and settings that DragonCrawl had to figure out. It would figure them out, but because there would be several steps required (rather than just 1 or 2 new steps), it would take much longer. Since our goal is to run DragonCrawl on every Android code change, we cannot afford those longer routes so we had to train Dragon to say no/skip certain things and say yes/confirm other things.
Hallucinations
Finally, a topic of much discussion is hallucinations in large language models. In the words of Yann LeCun, VP and Chief AI Scientist at Meta, large language models “kind of spew nonsense sometimes” (see article). Indeed, we need to be mindful that we cannot fully trust large language models, or at least not without guardrails. In this section, we will discuss the guardrails we put in place to prevent hallucinations from harming DragonCrawl.
First, one of DragonCrawl’s biggest strengths is the fact that it uses a smaller model. The size of our model is 110M parameters, which is roughly 3 orders of magnitude smaller than the popular GPT-3.5/4. Thus, this greatly reduces the variability and complexity of answers it can output. In other words, model size limits model non-sense.
Even so, we still received some invalid outputs, and here is how we handled them:
- Partially invalid actions: It may be possible for the model to return a response where some of the information is incorrect. For instance, it may return “touch” for a UI element that is swipeable; or it may output the right action and right location, but confuse the name of the UI element (i.e. request_trip_button). For either case, since we can read from the emulator the valid actions, the correct UI element names, etc., we can resolve confusions such as the ones mentioned before. The emulator provides us with the ground truth we can use to find the right actions given the name of a UI element; the correct location given the UI element name; and even the right UI element name, given the right location.
- Completely invalid actions: For completely invalid actions, we would append to the prompt the action previously suggested, and call out that it is invalid. This will result in a different action suggested by the model. For the case where invalid actions persist, we would backtrack and retry the suggestions from the model.
- Loops/repeated actions: We may end up in loops (i.e., scrolling up and down in a feed) or repeated actions (i.e., repeated waits). We handle this case by keeping track of the actions already taken in the specific sequence, and even screenshots, so it is really easy to figure out if we are in a loop. Also, since DragonCrawl outputs a list of suggestions, we can just try other suggested actions.
DragonCrawl in Action

We have seen DragonCrawl do amazing things, but in this section, we will discuss two scenarios that really impressed us.
DragonCrawl Goes Online in Australia!
In October 2023, we were testing Uber’s trip flow with DragonCrawl in Brisbane, Australia, and we saw something unexpected. DragonCrawl’s fake driver profile was perfectly set up but this time, it was not able to go online for around 5 minutes. During those 5 minutes, DragonCrawl pushed the “GO” online button repeatedly until it finally went online.

We were pleasantly surprised. DragonCrawl is so goal-oriented that it went through an unfriendly user experience to accomplish its goals: go online, be matched to a (fake) rider, and do the hypothetical trip. Because of the time to completion, we knew we had to investigate. We also learned, as discussed more below, that DragonCrawl will not be thrown off by minor or non-reproducible bugs, like the ones that impacted our script-based QA.
The ultimate solution: Turn it off, and then turn it back on
It was September 2023, and we saw Dragon do something so smart, we did not know if we should laugh or clap. Dragon was testing Uber’s trip flow in Paris. It chose to go to the Paris airport (CDG), and when it got to the screen to select the payment method, the payment methods were not loading (most likely a blip in the account we were using). What did Dragon do? It closed the app, opened it, and then requested the trip again. There were no issues the second time, so Dragon accomplished its goal of going to the airport.

It is difficult to express with words how excited and proud we are to see DragonCrawl do these things. Pushing the go online button repeatedly just to be able to drive with Uber, or opening and closing the app so that it can get to where it wants to be make DragonCrawl more resilient to minor tech issues than our old script-based testing model.
We have observed that no amount of code can match the goal-oriented behavior DragonCrawl displays, and what it represents for developer productivity is exciting. It is possible to create scripts that match DragonCrawl’s strategies, but how many thousands (or even millions) lines of code would need to be written? How expensive would it be to update all of that code when needed? Now, imagine what happens when traditional tests encounter the scenarios we just described:
- Functioning driver account cannot go online for 5 minutes: This would raise eyebrows if not alerts in testing teams. We may even think there is an outage, which would alert multiple engineers, but in reality, it is a transient issue.
- Payment method not loading: Tickets would be filed and at the highest priority. This would trigger multiple conversations, examinations, and attempts to reproduce the issue would be done, but it would only be a blip.
DragonCrawl Running on Uber’s CI
We productionized our model and the CI pipelines where the model has been consumed since around October 2023, and got some wins by the end of the year. As of January 2024, DragonCrawl executes the core-trip flow in 5 different cities once per night, and also for the Rider and Driver Android apps before releasing them to our customers. Since we launched, we have observed the following:
- High stability: DragonCrawl executed flows with 99%+ stability in November and December 2023. The rare cases where Dragon failed were due to outages in the third-party systems we use, and also due to a real outage caused by a high-priority bug that no other mobile testing tool detected.
- No maintenance: We did not need to manually update and/or maintain DragonCrawl. Whenever there were changes in the apps, DragonCrawl figured out how to get through those changes to accomplish its goals, unlike our team of software testers, who spent hundreds of hours maintaining test cases in 2023.
- High reusability: We evaluated DragonCrawl in 89 of our top cities, and DragonCrawl successfully requested and completed trips in 85 of them. This is the first time at Uber that a mobile test as complex as requesting and completing a trip has been successfully executed in 85 cities worldwide without needing to tweak code.
- Device/OS resilient: We tested Uber’s trip flow in our CI with 3 different kinds of Android devices, and 3 different OS versions, and we even varied other parameters, such as available disk, CPU, etc. DragonCrawl successfully requested and completed trips across all of these combinations without tweaks to our code or model, which is not always guaranteed in traditional mobile tests. Tuning tests to handle different screen sizes/resolutions and other device specifics is a known hassle of traditional mobile testing.
What’s Next?
The foundations we set in 2023 paved the way for a very exciting 2024 and beyond. Our investments in smaller language models resulted in a foundational model with very high-quality embeddings, to the point that it unlocks the architecture shown below:

With the Dragon Foundational Model (DFM), we can use small datasets (hundreds or tens of datapoints) and the DFM to create RAG (retrieval augmented generation) applications that more accurately simulate how humans interact with our applications. Those smaller datasets (with verbal goals and preferences), would tell DragonCrawl what to optimize for, and that is all it needs. The DFM may be a LLM, but it is secretly a rewards model that takes actions to accomplish its goals, and as we have seen, some of those actions mimic what a real human would do.
In 2024, a big area of investment for us will be to build the subsystems that will empower developers to build their tests as RAGs, and reap the benefits of flawlessly executing in many cities, languages, and with minimal (or even zero) maintenance costs.
Conclusion
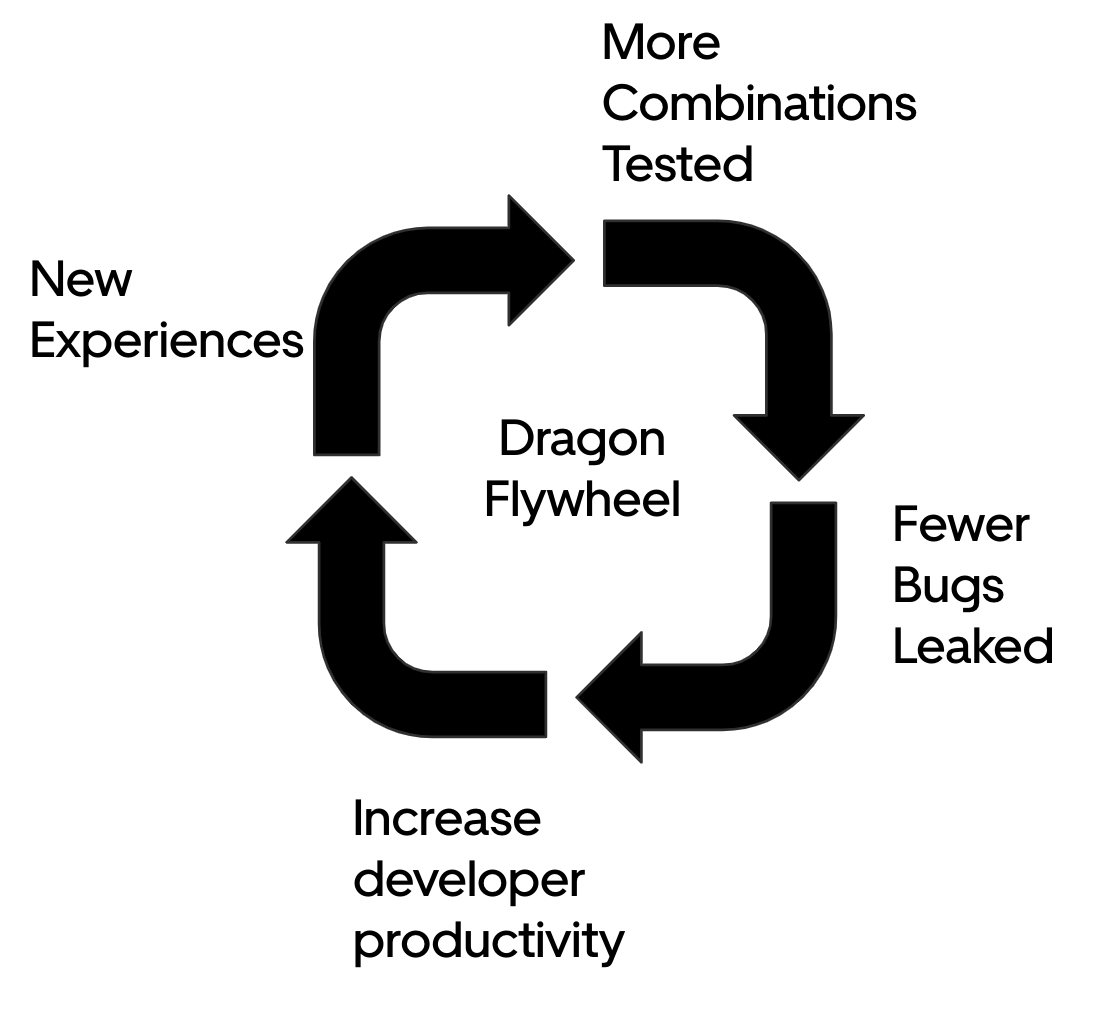
With all the advancements generative AI has seen over the past 4-6 months, there are more things to evaluate to improve our model and the quality of our apps. We plan to evaluate more modern large language models to push the quality of our models even further. Every increase in model quality will increase the combinations we can test, bringing down bugs that reach our users, which in turn increases productivity, enabling developers to build new experiences, and giving DragonCrawl more things to test. This is a flywheel that gets kicked off and accelerates with model quality, and we will fuel this acceleration.
Acknowledgments
Something as complex as DragonCrawl without the help of our partner teams. We are very thankful to Uber’s CI, Mobile Foundations, Michelangelo, Mobile Release and Test accounts. We would also like to thank you the passionate researchers that created MPNet (which we use), T5, and other LLMs for their contributions to the field and for enabling others to advance their own fields. We also want to thank Daniel Tsui and Sowjanya Puligadda for their leadership, advice and continued support, and finally to Srabonti Chakraborti and to our former intern Gustavo Nazario, who helped us turn DragonCrawl into what it is today.
Cover photo attribution: This image was generated using OpenAI’s DALL·E.
[ad_2]
Source link

