


[ad_1]

|
Update November, 16 2023 — I added a link to the documentation with the exact IAM permissions required to use this capability.
—
Today, we’re making available a new capability of AWS Glue Data Catalog to allow automatic compaction of transactional tables in the Apache Iceberg format. This allows you to keep your transactional data lake tables always performant.
Data lakes were initially designed primarily for storing vast amounts of raw, unstructured, or semi structured data at a low cost, and they were commonly associated with big data and analytics use cases. Over time, the number of possible use cases for data lakes has evolved as organizations have recognized the potential to use data lakes for more than just reporting, requiring the inclusion of transactional capabilities to ensure data consistency.
Data lakes also play a pivotal role in data quality, governance, and compliance, particularly as data lakes store increasing volumes of critical business data, which often requires updates or deletion. Data-driven organizations also need to keep their back end analytics systems in near real-time sync with customer applications. This scenario requires transactional capabilities on your data lake to support concurrent writes and reads without data integrity compromise. Finally, data lakes now serve as integration points, necessitating transactions for safe and reliable data movement between various sources.
To support transactional semantics on data lake tables, organizations adopted an open table format (OTF), such as Apache Iceberg. Adopting OTF formats comes with its own set of challenges: transforming existing data lake tables from Parquet or Avro formats to an OTF format, managing a large number of small files as each transaction generates a new file on Amazon Simple Storage Service (Amazon S3), or managing object and meta-data versioning at scale, just to name a few. Organizations are typically building and managing their own data pipelines to address these challenges, leading to additional undifferentiated work on infrastructure. You need to write code, deploy Spark clusters to run your code, scale the cluster, manage errors, and so on.
When talking with our customers, we learned that the most challenging aspect is the compaction of individual small files produced by each transactional write on tables into a few large files. Large files are faster to read and scan, making your analytics jobs and queries faster to execute. Compaction optimizes the table storage with larger-sized files. It changes the storage for the table from a large number of small files to a small number of larger files. It reduces metadata overhead, lowers network round trips to S3, and improves performance. When you use engines that charge for the compute, the performance improvement is also beneficial to the cost of usage as the queries require less compute capacity to run.
But building custom pipelines to compact and optimize Iceberg tables is time-consuming and expensive. You have to manage the planning, provision infrastructure, and schedule and monitor the compaction jobs. This is why we launch automatic compaction today.
Let’s see how it works
To show you how to enable and monitor automatic compaction on Iceberg tables, I start from the AWS Lake Formation page or the AWS Glue page of the AWS Management Console. I have an existing database with tables in the Iceberg format. I execute transactions on this table over the course of a couple of days, and the table starts to fragment into small files on the underlying S3 bucket.

I select the table on which I want to enable compaction, and then I select Enable compaction.
An IAM role is required to pass permissions to the Lake Formation service to access my AWS Glue tables, S3 buckets, and CloudWatch log streams. Either I choose to create a new IAM role, or I select an existing one. Your existing role must have lakeformation:GetDataAccess, glue:GetTable, and glue:UpdateTable permissions on the table. The role also needs logs:CreateLogGroup, logs:CreateLogStream, logs:PutLogEvents, to “arn:aws:logs:*:your_account_id:log-group:/aws-lakeformation-acceleration/compaction/logs:*“. The role trusted permission service name must be set to glue.amazonaws.com. The documentation has the full description of required IAM permissions.
Then, I select Turn on compaction. Et voilà! Compaction is automatic; there is nothing to manage on your side.
The service starts to measure the table’s rate of change. As Iceberg tables can have multiple partitions, the service calculates this change rate for each partition and schedules managed jobs to compact the partitions where this rate of change breaches a threshold value.
When the table accumulates a high number of changes, you will be able to view the Compaction history under the Optimization tab in the console.
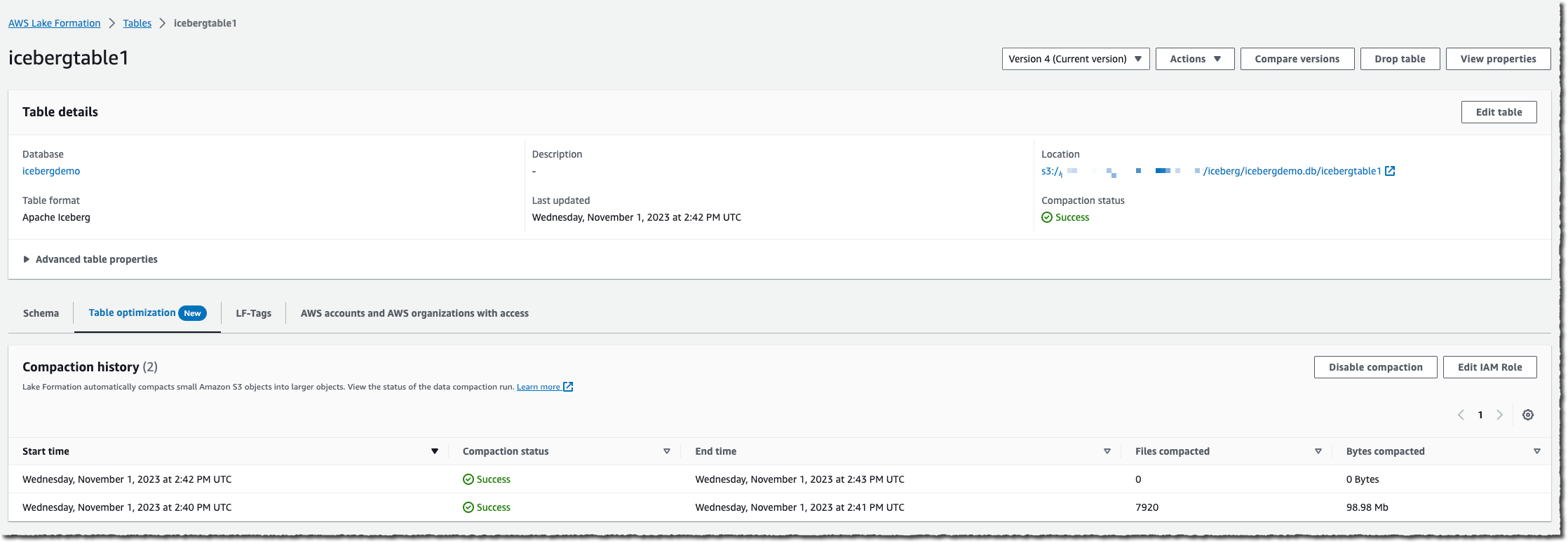
You can also monitor the whole process either by observing the number of files on your S3 bucket (use the NumberOfObjects metric) or one of the two new Lake Formation metrics: numberOfBytesCompacted or numberOfFilesCompacted.
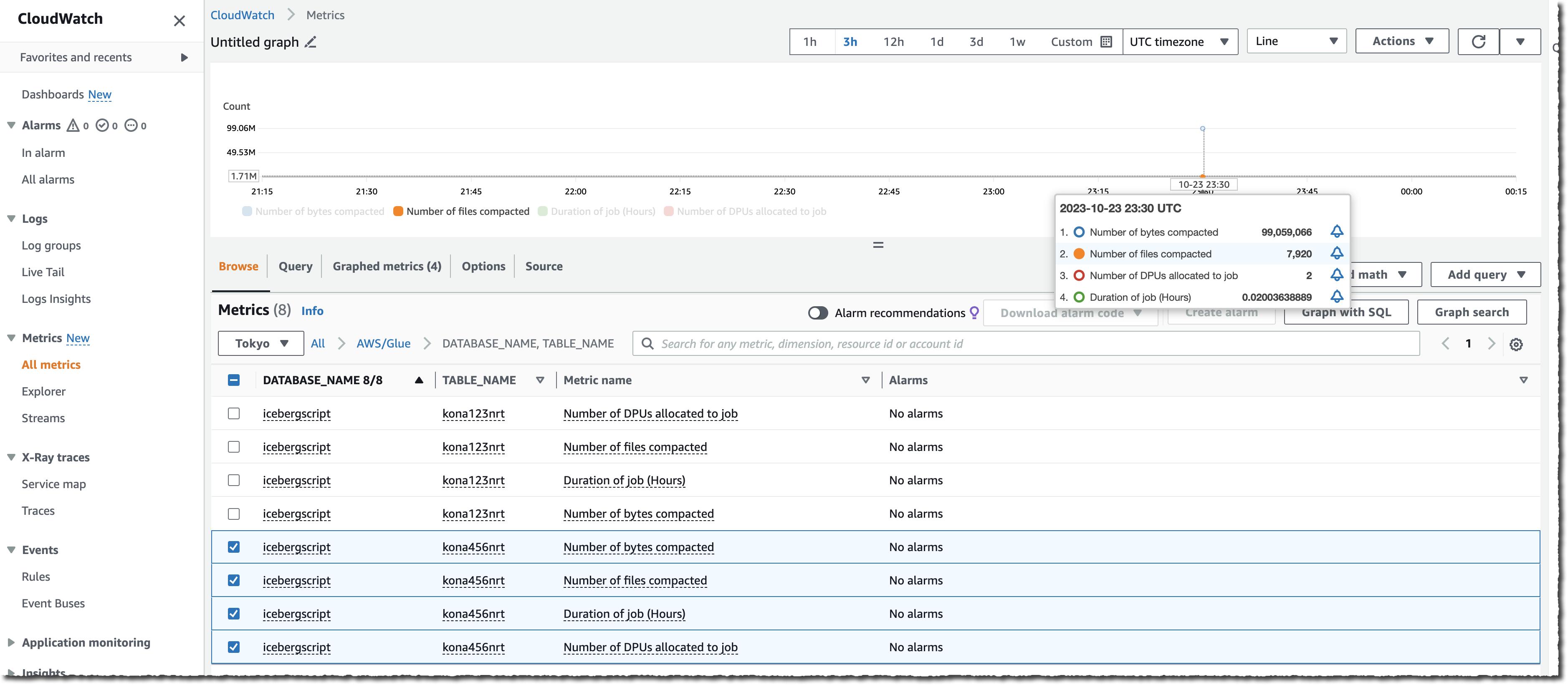
In addition to the AWS console, there are six new APIs that expose this new capability:CreateTableOptimizer, BatchGetTableOptimizer , UpdateTableOptimizer, DeleteTableOptimizer, GetTableOptimizer, and ListTableOptimizerRuns. These APIs are available in the AWS SDKs and AWS Command Line Interface (AWS CLI). As usual, don’t forget to update the SDK or the CLI to their latest versions to get access to these new APIs.
Things to know
As we launched this new capability today, there are a couple of additional points I’d like to share with you:
Availability
This new capability is available in US East (Ohio, N. Virginia), US West (Oregon), Asia Pacific (Tokyo), and Europe (Ireland).
The pricing metric is the data processing unit (DPU), a relative measure of processing power that consists of 4 vCPUs of compute capacity and 16 GB of memory. There is a charge per DPU/hours metered by second, with a minimum of one minute.
Now it’s time to decommission your existing compaction data pipeline and switch to this new, entirely managed capability today.
[ad_2]
Source link

