

[ad_1]
I’m excited to announce today a new capability of Amazon Managed Streaming for Apache Kafka (Amazon MSK) that allows you to continuously load data from an Apache Kafka cluster to Amazon Simple Storage Service (Amazon S3). We use Amazon Kinesis Data Firehose—an extract, transform, and load (ETL) service—to read data from a Kafka topic, transform the records, and write them to an Amazon S3 destination. Kinesis Data Firehose is entirely managed and you can configure it with just a few clicks in the console. No code or infrastructure is needed.
Kafka is commonly used for building real-time data pipelines that reliably move massive amounts of data between systems or applications. It provides a highly scalable and fault-tolerant publish-subscribe messaging system. Many AWS customers have adopted Kafka to capture streaming data such as click-stream events, transactions, IoT events, and application and machine logs, and have applications that perform real-time analytics, run continuous transformations, and distribute this data to data lakes and databases in real time.
However, deploying Kafka clusters is not without challenges.
The first challenge is to deploy, configure, and maintain the Kafka cluster itself. This is why we released Amazon MSK in May 2019. MSK reduces the work needed to set up, scale, and manage Apache Kafka in production. We take care of the infrastructure, freeing you to focus on your data and applications. The second challenge is to write, deploy, and manage application code that consumes data from Kafka. It typically requires coding connectors using the Kafka Connect framework and then deploying, managing, and maintaining a scalable infrastructure to run the connectors. In addition to the infrastructure, you also must code the data transformation and compression logic, manage the eventual errors, and code the retry logic to ensure no data is lost during the transfer out of Kafka.
Today, we announce the availability of a fully managed solution to deliver data from Amazon MSK to Amazon S3 using Amazon Kinesis Data Firehose. The solution is serverless–there is no server infrastructure to manage–and requires no code. The data transformation and error-handling logic can be configured with a few clicks in the console.
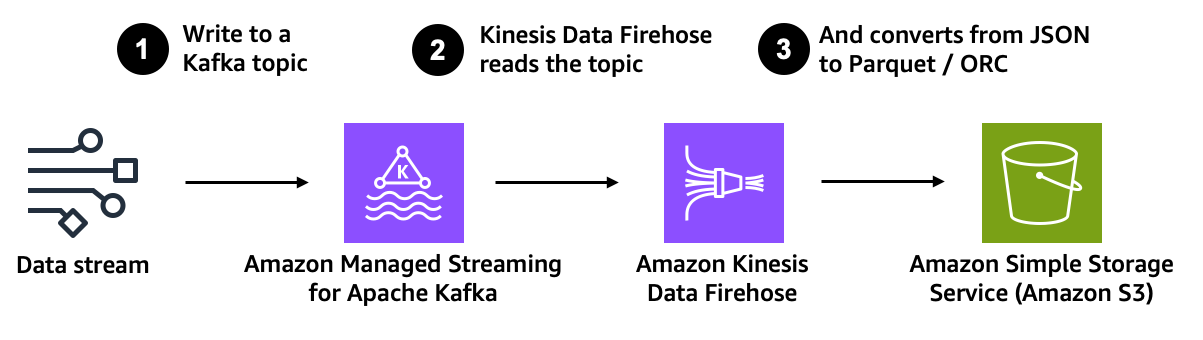
The architecture of the solution is illustrated by the following diagram.

Amazon MSK is the data source, and Amazon S3 is the data destination while Amazon Kinesis Data Firehose manages the data transfer logic.
When using this new capability, you no longer need to develop code to read your data from Amazon MSK, transform it, and write the resulting records to Amazon S3. Kinesis Data Firehose manages the reading, the transformation and compression, and the write operations to Amazon S3. It also handles the error and retry logic in case something goes wrong. The system delivers the records that can not be processed to the S3 bucket of your choice for manual inspection. The system also manages the infrastructure required to handle the data stream. It will scale out and scale in automatically to adjust to the volume of data to transfer. There are no provisioning or maintenance operations required on your side.
Kinesis Data Firehose delivery streams support both public and private Amazon MSK provisioned or serverless clusters. It also supports cross-account connections to read from an MSK cluster and to write to S3 buckets in different AWS accounts. The Data Firehose delivery stream reads data from your MSK cluster, buffers the data for a configurable threshold size and time, and then writes the buffered data to Amazon S3 as a single file. MSK and Data Firehose must be in the same AWS Region, but Data Firehose can deliver data to Amazon S3 buckets in other Regions.
Kinesis Data Firehose delivery streams can also convert data types. It has built-in transformations to support JSON to Apache Parquet and Apache ORC formats. These are columnar data formats that save space and enable faster queries on Amazon S3. For non-JSON data, you can use AWS Lambda to transform input formats such as CSV, XML, or structured text into JSON before converting the data to Apache Parquet/ORC. Additionally, you can specify data compression formats from Data Firehose, such as GZIP, ZIP, and SNAPPY, before delivering the data to Amazon S3, or you can deliver the data to Amazon S3 in its raw form.
Let’s See How It Works
To get started, I use an AWS account where there’s an Amazon MSK cluster already configured and some applications streaming data to it. To get started and to create your first Amazon MSK cluster, I encourage you to read the tutorial.
For this demo, I use the console to create and configure the data delivery stream. Alternatively, I can use the AWS Command Line Interface (AWS CLI), AWS SDKs, AWS CloudFormation, or Terraform.
I navigate to the Amazon Kinesis Data Firehose page of the AWS Management Console and then choose Create delivery stream.
I select Amazon MSK as a data Source and Amazon S3 as a delivery Destination. For this demo, I want to connect to a private cluster, so I select Private bootstrap brokers under Amazon MSK cluster connectivity.
I need to enter the full ARN of my cluster. Like most people, I cannot remember the ARN, so I choose Browse and select my cluster from the list.
Finally, I enter the cluster Topic name I want this delivery stream to read from.

After the source is configured, I scroll down the page to configure the data transformation section.
On the Transform and convert records section, I can choose whether I want to provide my own Lambda function to transform records that aren’t in JSON or to transform my source JSON records to one of the two available pre-built destination data formats: Apache Parquet or Apache ORC.
Apache Parquet and ORC formats are more efficient than JSON format to query data from Amazon S3. You can select these destination data formats when your source records are in JSON format. You must also provide a data schema from a table in AWS Glue.
These built-in transformations optimize your Amazon S3 cost and reduce time-to-insights when downstream analytics queries are performed with Amazon Athena, Amazon Redshift Spectrum, or other systems.

Finally, I enter the name of the destination Amazon S3 bucket. Again, when I cannot remember it, I use the Browse button to let the console guide me through my list of buckets. Optionally, I enter an S3 bucket prefix for the file names. For this demo, I enter aws-news-blog. When I don’t enter a prefix name, Kinesis Data Firehose uses the date and time (in UTC) as the default value.
Under the Buffer hints, compression and encryption section, I can modify the default values for buffering, enable data compression, or select the KMS key to encrypt the data at rest on Amazon S3.
When ready, I choose Create delivery stream. After a few moments, the stream status changes to  available.
available.

Assuming there’s an application streaming data to the cluster I chose as a source, I can now navigate to my S3 bucket and see data appearing in the chosen destination format as Kinesis Data Firehose streams it.
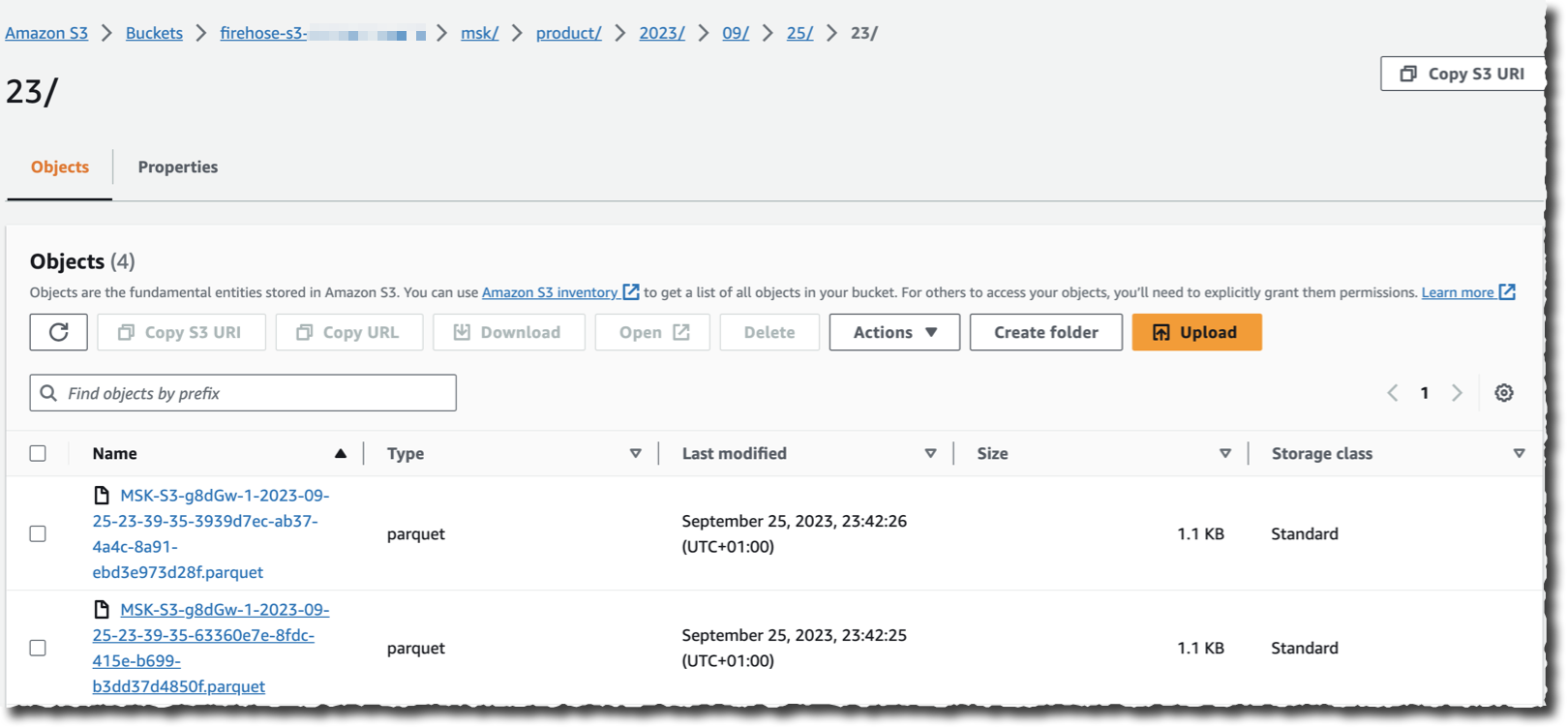
As you see, no code is required to read, transform, and write the records from my Kafka cluster. I also don’t have to manage the underlying infrastructure to run the streaming and transformation logic.
Pricing and Availability.
This new capability is available today in all AWS Regions where Amazon MSK and Kinesis Data Firehose are available.
You pay for the volume of data going out of Amazon MSK, measured in GB per month. The billing system takes into account the exact record size; there is no rounding. As usual, the pricing page has all the details.
I can’t wait to hear about the amount of infrastructure and code you’re going to retire after adopting this new capability. Now go and configure your first data stream between Amazon MSK and Amazon S3 today.
— seb
[ad_2]
Source link


