


[ad_1]

|
Today, we announced the general availability of Amazon SageMaker Lakehouse and Amazon Redshift support for zero-ETL integrations from applications. Amazon SageMaker Lakehouse unifies all your data across Amazon Simple Storage Service (Amazon S3) data lakes and Amazon Redshift data warehouses, helping you build powerful analytics and AI/ML applications on a single copy of data. SageMaker Lakehouse gives you the flexibility to access and query your data in-place with all Apache Iceberg compatible tools and engines. Zero-ETL is a set of fully managed integrations by AWS that minimizes the need to build ETL data pipelines for common ingestion and replication use cases. With zero-ETL integrations from applications such as Salesforce, SAP, and Zendesk, you can reduce time spent building data pipelines and focus on running unified analytics on all your data in Amazon SageMaker Lakehouse and Amazon Redshift.
As organizations rely on an increasingly diverse array of digital systems, data fragmentation has become a significant challenge. Valuable information is often scattered across multiple repositories, including databases, applications, and other platforms. To harness the full potential of their data, businesses must enable access and consolidation from these varied sources. In response to this challenge, users build data pipelines to extract and load (EL) from multiple applications into centralized data lakes and data warehouses. Using zero-ETL, you can efficiently replicate valuable data from your customer support, relationship management, and enterprise resource planning (ERP) applications for analytics and AI/ML to datalakes and data warehouses, saving you weeks of engineering effort needed to design, build, and test data pipelines.
Prerequisites
- An Amazon SageMaker Lakehouse catalog configured through AWS Glue Data Catalog and AWS Lake Formation.
- An AWS Glue database that is configured for Amazon S3 where the data will be stored.
- A secret in AWS Secret Manager to use for the connection to the data source. The credentials must contain the username and password that you use to sign in to your application.
- An AWS Identity and Access Management (IAM) role for the Amazon SageMaker Lakehouse or Amazon Redshift job to use. The role must grant access to all resources used by the job, including Amazon S3 and AWS Secrets Manager.
- A valid AWS Glue connection to the desired application.
How it works – creating a Glue connection prerequisite
I start by creating a connection using the AWS Glue console. I opt for a Salesforce integration as the data source.

Next, I provide the location of the Salesforce instance to be used for the connection, together with the rest of the required information. Be sure to use the .salesforce.com domain instead of .force.com. Users can choose between two authentication methods, JSON Web Token (JWT), which is obtained through Salesforce access tokens, or OAuth login through the browser.

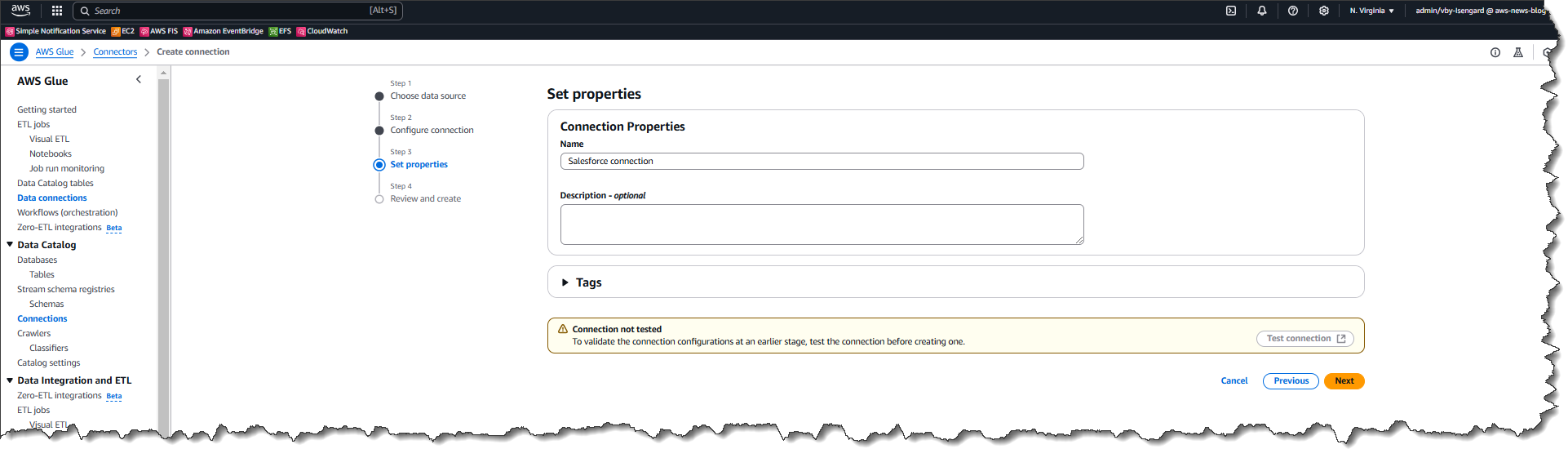
I review all the information and then choose Create connection.

After I sign into the Salesforce instance through a popup (not shown here), the connection is successfully created.

How it works – creating a zero-ETL integration
Now that I have a connection, I choose zero-ETL integrations from the left navigation panel, then choose Create zero-ETL integration.
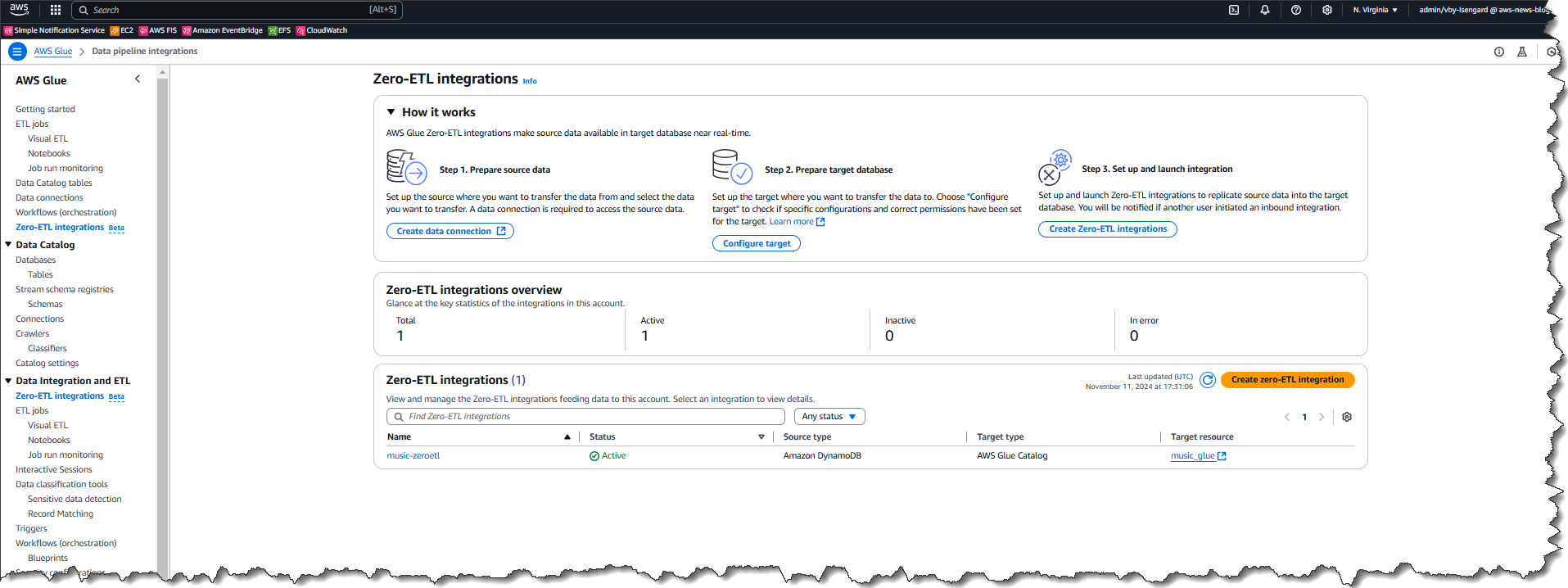
First I choose the source type for my integration – in this case Salesforce so I can use my recently created connection.

Next, I select objects from the data source that I want to replicate to the target database in AWS Glue.
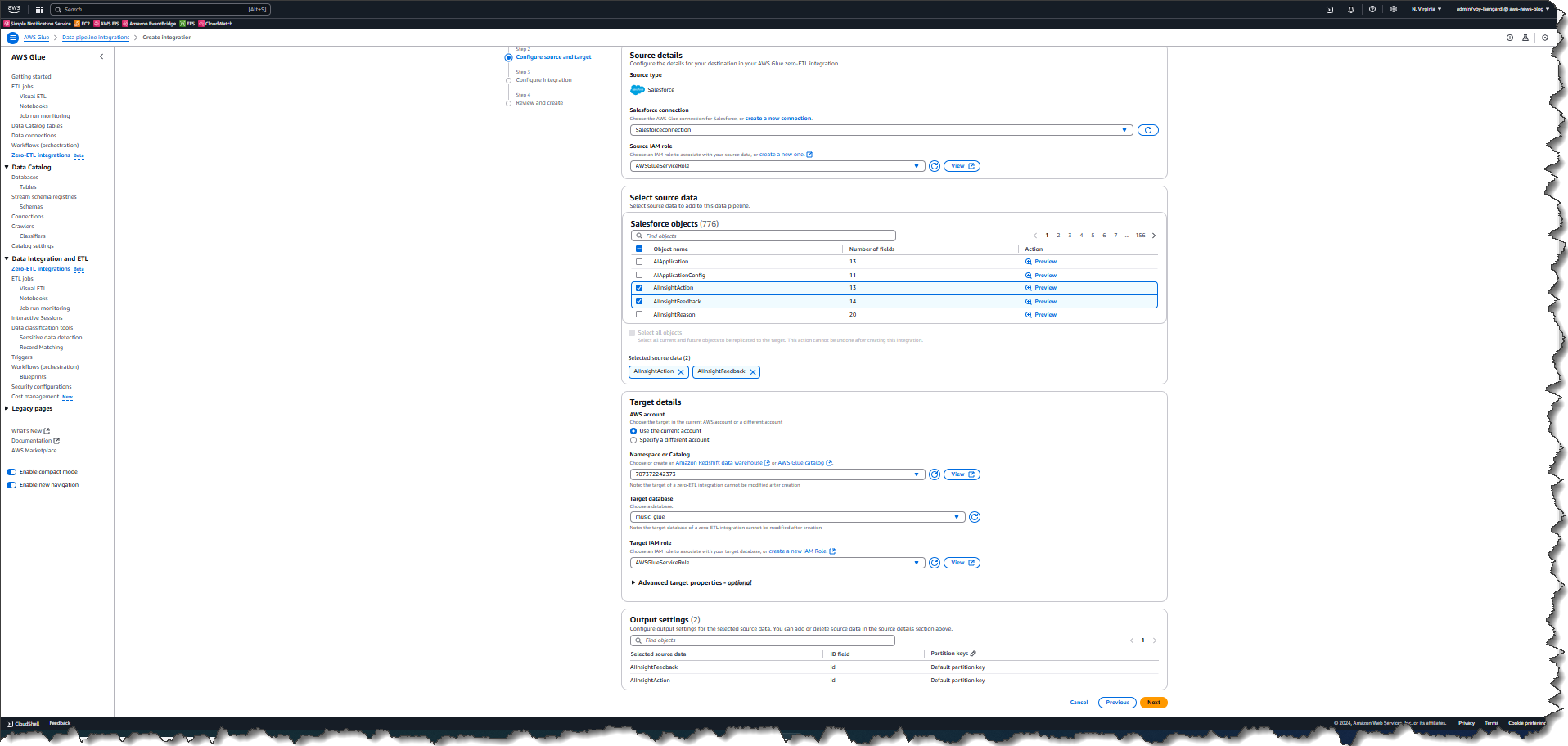
While in the process of adding objects, I can quickly preview both data and metadata to confirm that I am selecting the correct object.
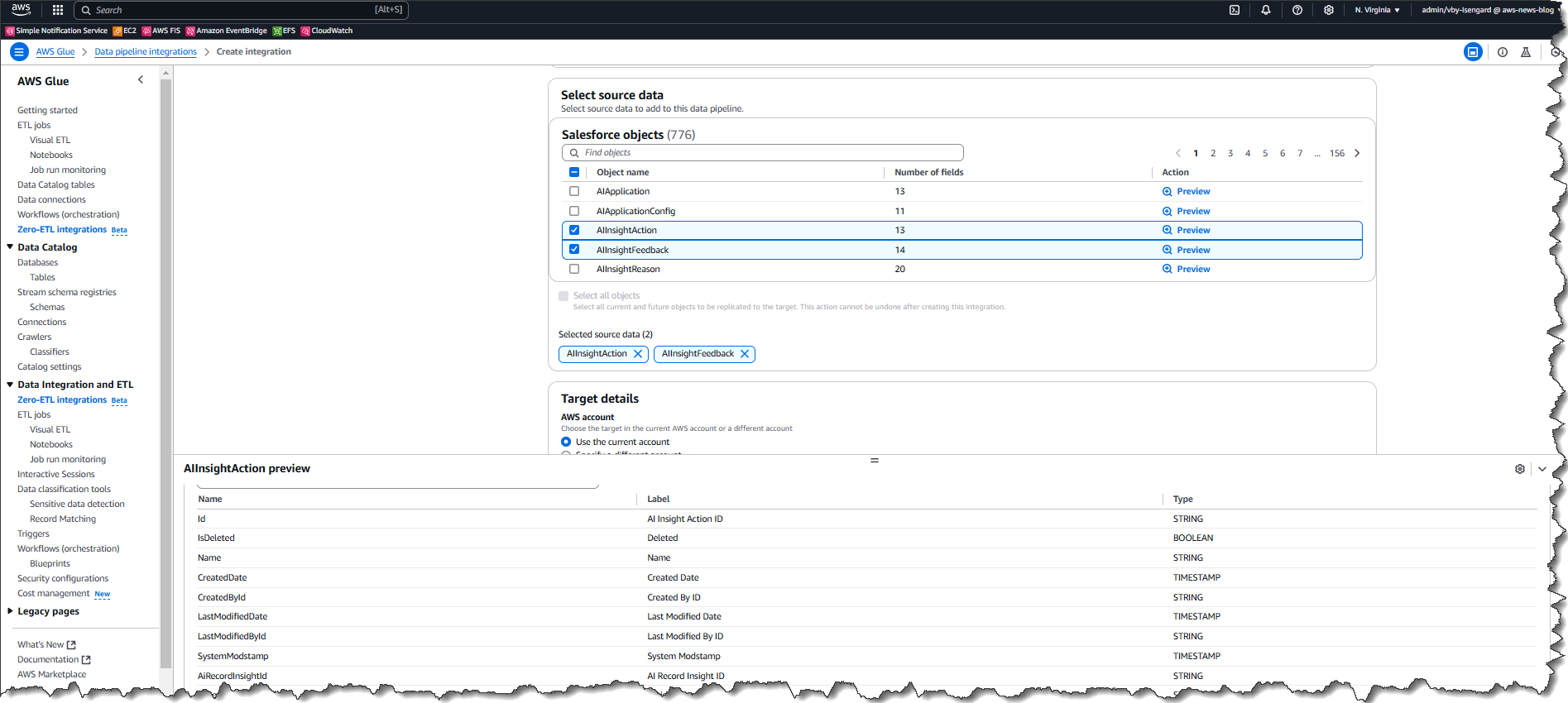
By default, zero-ETL integration will synchronize data from the source to the target every 60 minutes. However, you can change this interval to reduce the cost of replication for cases that do not require frequent updates.
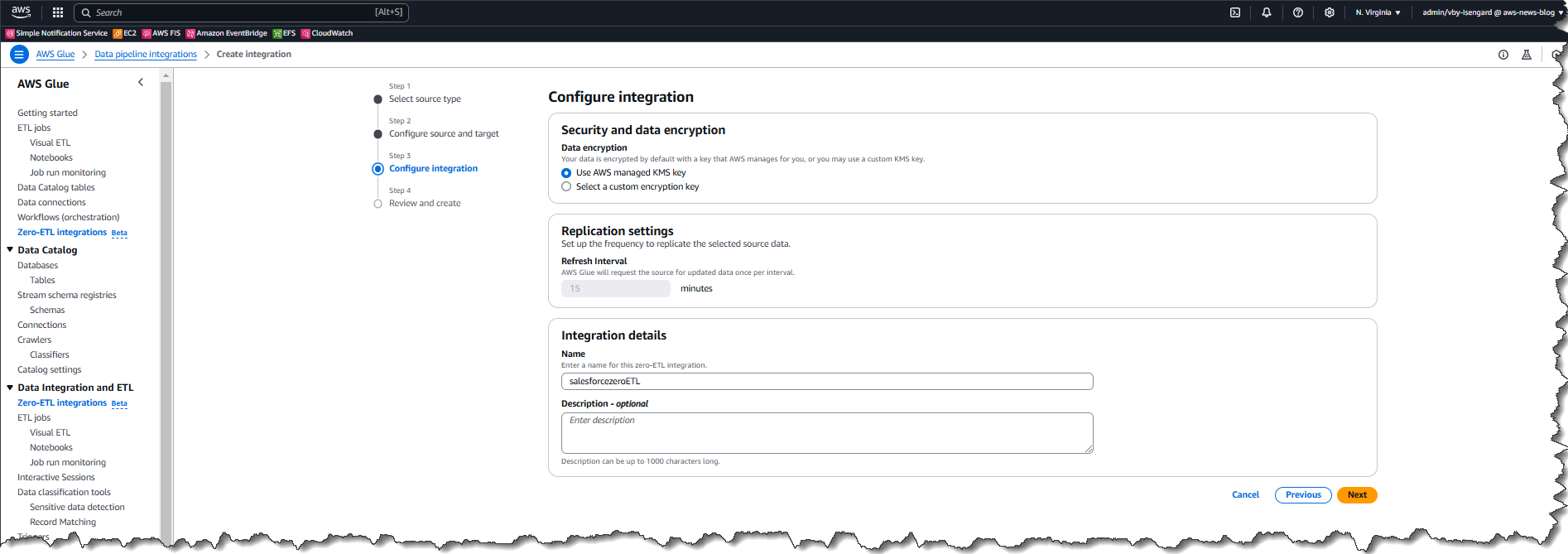
I review and then choose Create and launch integration.
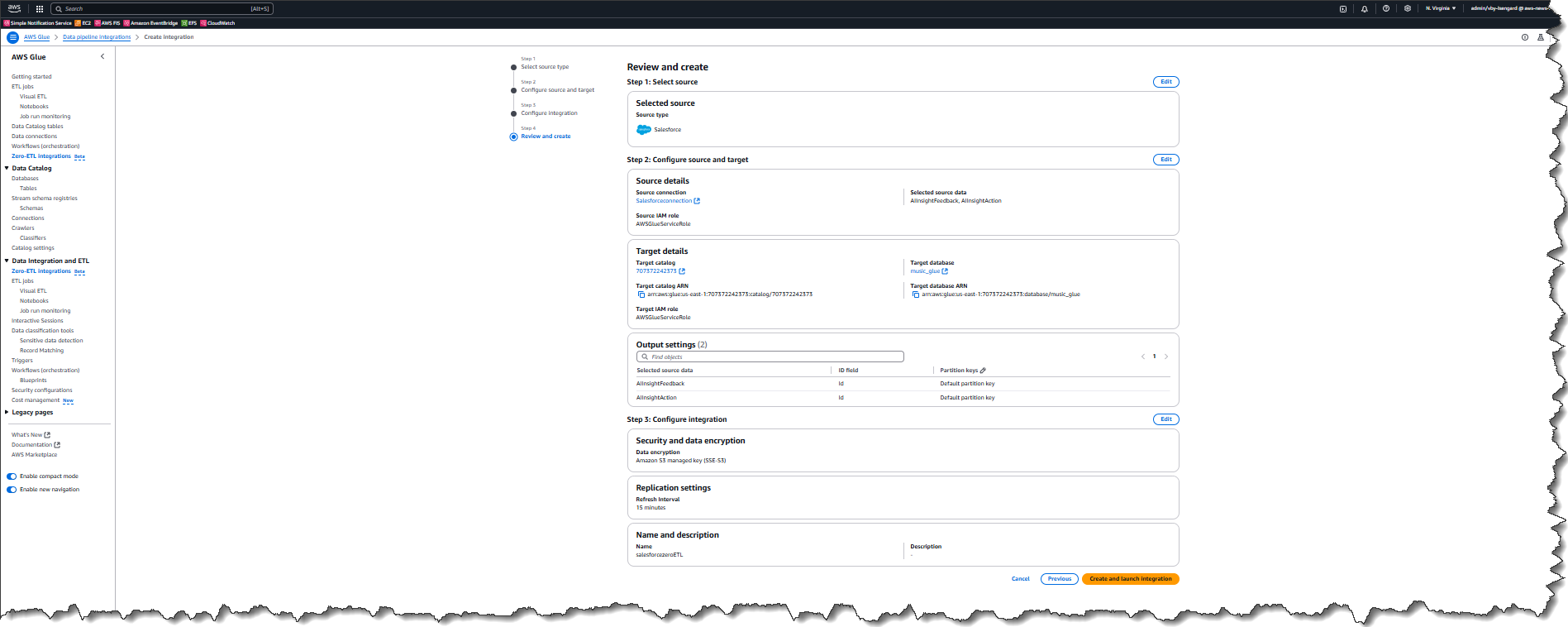
The data in the source (Salesforce instance) has now been replicated to the target database salesforcezeroETL in my AWS account. This integration has two phases. Phase 1: initial load will ingest all the data for the selected objects and may take between 15 min to a few hours depending on the size of the data in these objects. Phase 2: incremental load will detect any changes (such as new records, updated records, or deleted records) and apply these to the target.
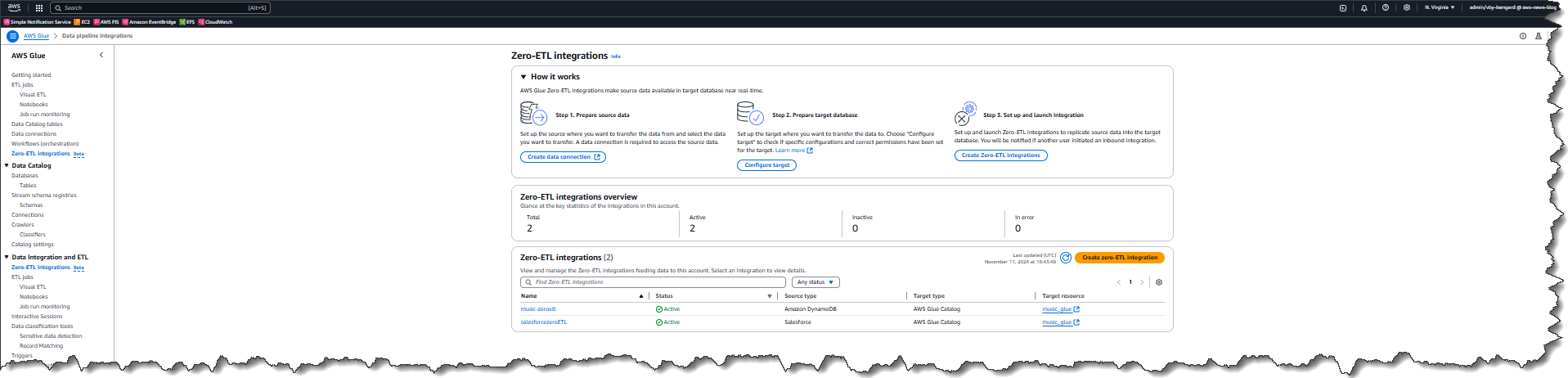
Each of the objects that I selected earlier has been stored in its respective table within the database. From here I can view the Table data for each of the objects that have been replicated from the data source.
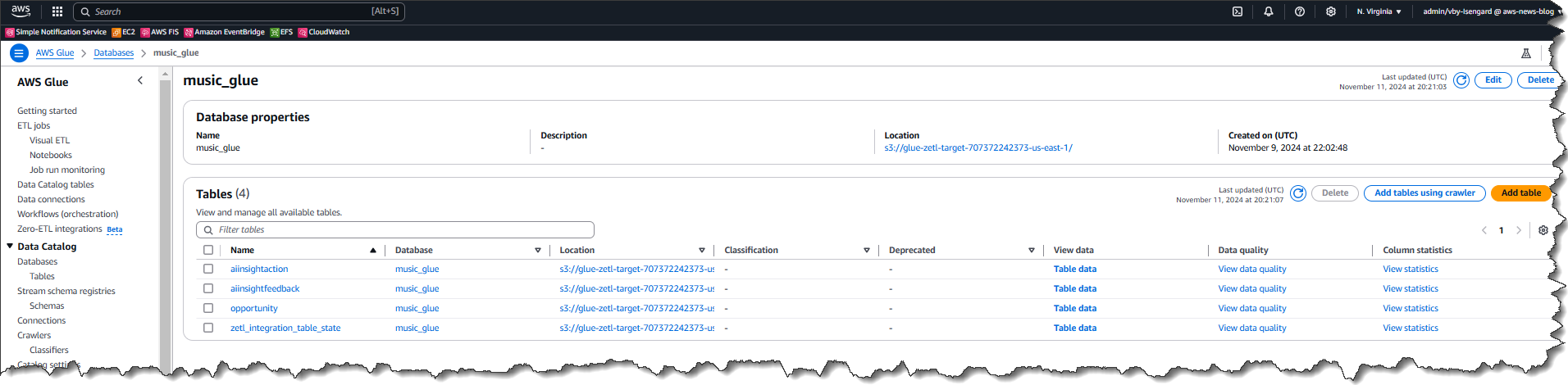

Lastly, here’s a view of the data in Salesforce. As new entities are created, or existing entities are updated or changed in Salesforce, the data changes will synchronize to the target in AWS Glue automatically.

Now available
Amazon SageMaker Lakehouse and Amazon Redshift support for zero-ETL integrations from applications is now available in US East (N. Virginia), US East (Ohio), US West (Oregon), Asia Pacific (Hong Kong), Asia Pacific (Singapore), Asia Pacific (Sydney), Asia Pacific (Tokyo), Europe (Frankfurt), Europe (Ireland), and Europe (Stockholm) AWS Regions. For pricing information, visit the AWS Glue pricing page.
To learn more, visit our AWS Glue User Guide. Send feedback to AWS re:Post for AWS Glue or through your usual AWS Support contacts. Get started by creating a new zero-ETL integration today.
– Veliswa
[ad_2]
Source link



