


[ad_1]
Introduction
Data categorization–the process of classifying data based on its characteristics and essence–is a foundational pillar of any privacy or security program. The effectiveness of fine-grained data categorization is pivotal in implementing privacy and security controls, such as access policies and encryption, as well as managing the lifecycle of data assets, encompassing retention and deletion. This blog delves into Uber’s approach to achieving data categorization at scale by leveraging various AI/ML techniques.
Why auto-categorization?
- Sheer Scale and Cost: Many companies manage extensive datasets distributed across various storage systems. This scale is compounded by the generation of new datasets regularly. Central to our challenge is tagging numerous columns at the field level, each potentially requiring multiple tags. Manual tagging demands significant time and resources. Additionally, an ongoing investment is required to tag newly created datasets.
- Engagement of Data Owners: Identifying and engaging data owners presents a complex reality. With multiple tags to evaluate for each data element, it becomes intricate and time-consuming to discern nuances among tag definitions, leading to miscategorization.
Given the monumental engineering cost and the impracticality of manual categorization through decentralized efforts, our experiences have led us to prioritize auto-categorization. In response, we have introduced a novel solution named DataK9, an automatic categorization platform for Uber data. The primary objective is minimizing and eliminating user involvement, thereby addressing the challenges posed by scale, cost, and data owner engagement.
Challenges
Consider a table with a single column comprising purely numeric content. Merely examining the data itself makes it impossible to discern the nature of these numbers, which could represent latitude, longitude, exchange rates, and more.

However, if we are privy to the column name, such as Latitude and Longitude in Figure 1, it significantly aids in categorizing these columns accurately.
Nevertheless, challenges persist, particularly when the column name is generic, as illustrated by the recently added Note column in Figure 2. This could potentially contain information ranging from balance and cost to the distance between two locations.

Moreover, even within the same type of location data, categorization can be nuanced based on precision. For instance, a location with latitude and longitude specified to three or more decimal places may be deemed a precise location. If linked to personal identification, it could warrant classification under the Highly Restricted category.
Let’s delve into another example in Figure 3:

In the absence of explicit context, it becomes challenging to differentiate between personal and business addresses, despite both being addresses.
Given these complexities, there is no universal solution to address all categorization challenges. Therefore, we have opted to leverage a probabilistic-based approach (i.e., AI/ML) to provide assistance in this endeavor.
Strategy
The application of AI/ML techniques forms the bedrock of our auto-categorization initiative. In this section, we present the overarching strategy, delineating the broader flows and dependencies across various systems within the new framework.
Evaluating the efficacy of the new automation process is critical and hinges on a small fraction (<1%) of labeled (golden) datasets. These datasets are categorized manually, preferably by domain experts or owners. The auto-categorization mechanism then leverages this vetted training data to tag the remaining dataset (>99%). In essence, the solution adopts a hybrid approach, combining manual categorization with automation, encapsulated in three interconnected stages illustrated in the diagram Figure 4 below.
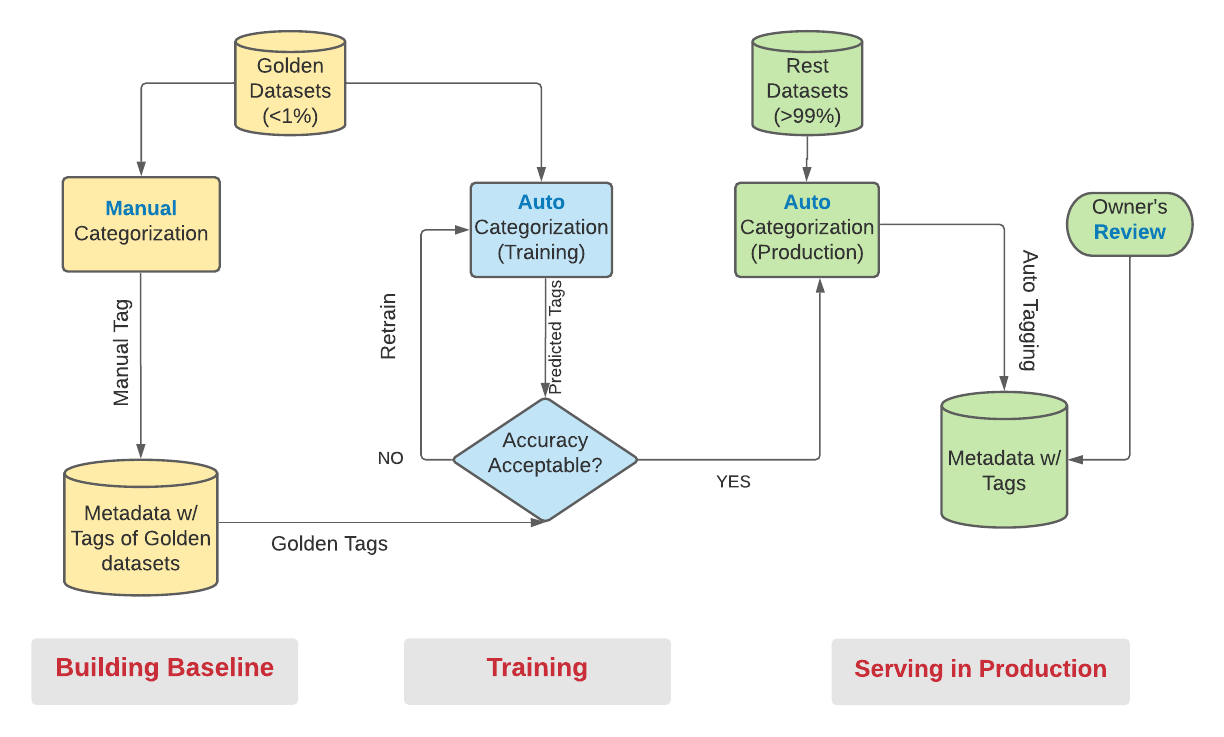
Building Baseline
We suggest categorizing <1% of datasets (nearly 1,000) as critical and highly utilized tables by humans with close supervision from privacy and domain experts. Those datasets are treated as the “golden” datasets, with high categorization accuracy, and are used to measure automation accuracy. Although the number of “golden” datasets is relatively small, there are some significant benefits:
- Model Training: Training is the most critical step of any supervised machine learning-based solution. Without a properly trained model, machines wouldn’t even know what to comprehend in the first place. We utilize the manually categorized data as the baseline for our AI approach.
- Risk Mitigation: We have a few business-critical datasets that we don’t want to risk due to mistagging. That’s why we manually tag those highly impactful datasets by owners or experts.
The selection of datasets for labeling should ideally be done randomly to avoid, as much as possible, statistical biases inserted into the labeled datasets. Such statistical biases reduce the reliability of offline model performance testing, and may cause systemic classification errors in production.
Training
For the rest of the 99% of datasets (>400K), we will primarily utilize a new automation system called DataK9 (detailed in the later sub-section). At first, DataK9 is trained against the manually categorized (golden) datasets until the accuracy reaches a satisfactory level without over-tuning. In particular, there will be two sub-stages:
- We iteratively train a model based on a subset of golden datasets and then run the model against the rest of the golden datasets (test data). We analyzed standard metrics after every test run (i.e., accuracy, precision, recall, F2-score, etc.). If the metrics are not acceptable, we tune the model and rerun/reevaluate it until we get a satisfactory result.
- A list of detection rules to tag the data are created by domain experts. After a rule is defined, it continually goes through a test run and rule adjustment until acceptable metrics values are achieved. The initial rule definition and early rule iterations will have more human involvement. We will gradually move into rules’ auto-adjustment where we automate the adjustment process and roll out rule changes where they result in better predictions.
Serving in Production
After Datak9 demonstrates its satisfactory metrics (i.e., accuracy >90%, F2-score >85%) for the training datasets, it will be ready for production tagging of the rest datasets. However, we plan to take some defensive processes at the early stage of mass categorization. It includes automatic ticket creation to review (preferable for data owners or trained privacy experts) after a dataset is (tentatively) auto-categorized. When the owner stamps it, the categorization will be deemed as final. In addition, during this transition phase, we will closely monitor the progress, most notably the miss-categorization rate. If the feedback from the reviewers is acceptable, we will go for mass deployment of hundreds of thousands of datasets.
Architecture
This section describes the architecture of the AI-based core platform and how DataK9 adopts ML/AI technologies in different parts and stages of the framework as illustrated in Figure 5. We focus on the primary use case of tagging a dataset in this section. It starts with identifying and gathering the essential features of a dataset, followed by the ML/AI technique to determine a column’s weight/score for a specific tag. Then, we discuss how to combine multiple signals for a particular field into the final decision. At last, we detail the active learning process to tune the rules and ML model based on the mistakes made in the original tagging.
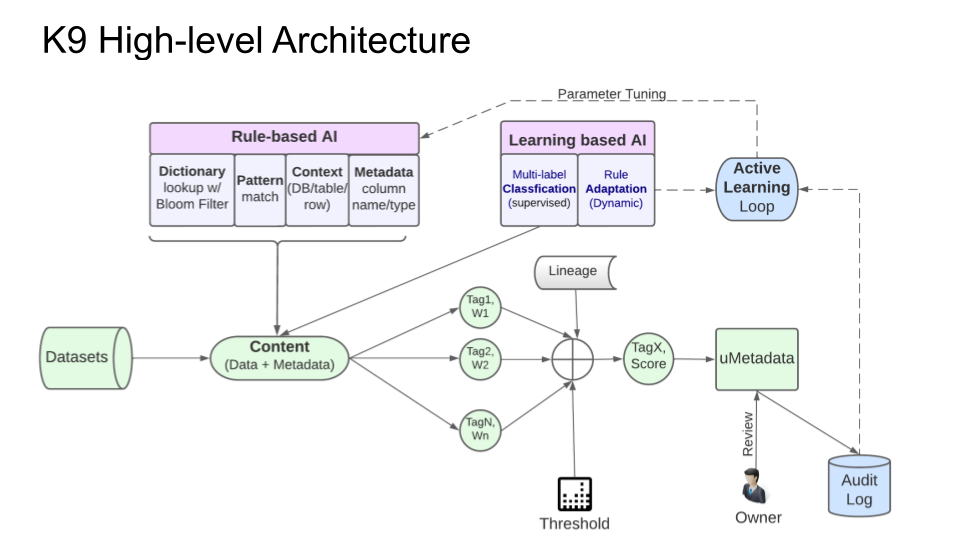
Key Features
DataK9 consumes the following information of a dataset that we could use as a potential feature in our various ML/AI classification techniques:
- Metadata: It includes the name and type of each field within a dataset. For instance, the dataset “uber_rides” could have 100+ fields. DataK9 utilizes all the fields’ names such as “request_latitude” and “email” and the associated types such as double and string.
- Data: A dataset could contain billions of records. Although DataK9 would eventually consider the contents of all rows, we will start with a random sample of records (~1%) for each run/scan of a dataset. More specifically, we will utilize the cell-content to determine a column category.
- Context: While each cell value provides valuable information, other values in the same record could give additional signals. In addition, the context, such as the table and database name, renders hints about the column’s tag.
- Lineage: Data lineage is a map of the data journey, including its origin, creation process, etc. There are two types of data lineage information that are relevant for DataK9.
- Table-level Lineage: Table lineage will provide the higher-level information, such as what tables were used to create a new table. For example, the table “uber_rides” is created after joining a handful of tables such as drivers and riders. This type of lineage is more relevant for the derived table than the raw table.
- Column-Level Lineage: This lineage refers to which column is derived from what set of dependent columns of different tables. Collecting this information is more involved for various data processing platforms such as Hive™, Spark™, etc. However, DataK9 can better predict the tag if a reliable column-level lineage is available.
Matching Strategy
The essence of the proposed solution is to crawl data (table or directory, or file) eventually from all data stores and scan each data element periodically to get signals for different tags. We discuss some fundamental matching techniques in this section.
- Individual vs. Aggregate Decision: DataK9 scans data at the cell level and looks for signals from the contents and metadata. Since there are millions of data elements, DataK9 would check each element and get the respective indication. For example, assume there is a cell value of john@gmail.com. We will match this email address against each tag and generate a matching score for this value. However, making the final decision based on one matching score may be misleading. In reality, the email address could be in another column (such as promotion_code), which may not be construed as PII data. Moreover, our primary goal is to tag the columns of a table–not the individual column values. Therefore, we combine these individual scores of all column values into a global one and ultimately decide. For example, if 80% of a column’s values have an email match, we can safely assume the column contains email PII data and tag it accordingly.
- Probabilistic Decision: DataK9 looks for specific matches for a particular tag. However, there is hardly a case where finding a match will assure the tag assignment. Hence, we define a score for each check. The higher the score, the higher the possibility of a tag association.
- Negative Score: DataK9 allows negative scoring to signal that it is unlikely be part of a specific tag. For example, any data under the database name pattern “products” is unlikely to have any PII data.
Rule-Based AI
As we crawl a new dataset, we apply the two AI approaches against the sample data and then identify each field/column category. We explain the rule-based in this section, followed by the learning-based in the next section.
We will start with a set of hand-crafted rules and build an associated rule language and engine. It is challenging to find a domain expert with the proper knowledge and experiences, such as a deep understanding of data contents, categorization internals, and engineering chops. Essentially designing a rule considers two critical dimensions: 40+ different tags and fundamental features. We support the following building blocks to express a rule:
- Bloom filter match: We create a bloom filter from the most common data values for a specific entity. Then during the scanning of each column value, we test the membership and decide the possible tag. For example, we can create a bloom filter for all addresses that Uber delivery services used in the last month. Then, during scanning, we can test the membership of each cell of data to find a possible match.
- Dictionary match: We create a dictionary with a list of commonly used values. During scanning, K9 looks up the dictionary for each data element (cells) of a dataset and decides the match score according to the rule definition. For instance, we can create a dictionary to include 750+ airport codes to match location information.
- Pattern match: We define a regular expression to find a match against the content of a column or the column name. For instance, we can use the pattern ^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$ to match email addresses like john@gmail.com. It is important to note that the pattern match may not be sufficient to determine the final tag in some situations.
- Context matching: The column name and value alone may not provide any strong signal about its content type. Therefore, we allow looking for the context beyond the cell value itself. We will support three different contexts:
- Record level: The rationale is that some data tags may come with other data tags in the same dataset. For example, suppose there is a latitude value in a column. In that case, it is considered a non-sensitive location data because the same latitude could be there for millions of location points. Therefore, we should look for longitude as well in the same record.
- Table level: In some instances, the table name patterns play an important role in determining the data type for some instances. For example, the full name in the “virtual_machine” table is not sensitive, whereas it is very sensitive for the “rider” table (holds end-users data).
- Database level: Some database name patterns could dictate what types of data the DB may contain. For example, if the database has “finance” in its name, it will likely include some transaction data.
- Data type match: Data type matches include the list of possible data types of a category. If any field doesn’t obey the type restriction of a tag, K9 will skip that column matching for that tag. For example, a personal email column is of type string; therefore, we don’t need to check for the email category if the column’s data type is non-string. This type of check happens less frequently once per file or dataset because it is at the metadata level.
Rule Language
Defining a rule is the first step for rule-based AI, and supporting a standard rule definition language or template is imperative. This section describes the essential building blocks to define a rule for a specific tag.
- There are three broader sub-rules in a rule depending on the type of data it checks: column value match (columnValueMatch), metadata match (columnNameMatch), and contextual match (contextMatch).
- Each sub-rule will have a matching “score” specified by the rule admin based on her domain expertise.
- columnValueMatch rule mainly checks the values of each data element in a dataset. These operations are costly and involved because the number of data elements and the number of checks per value is enormous. It entails the following filter and checks:
- The bloom filter section contains the configurations required to find the pre-calculated bloom filter to check the membership and the associate score. We can store the bloom filter in a file or table.
- Dictionary match looks for the exact match from a predefined list of most commonly used values. This dictionary can be an HDFS file or Hive table.
- lengthRange defines the length of the content. This filter can easily exclude a lot of values from expensive matches early. For example, the length of a latitude value could be between 3 to 10. K9 should not consider any content outside this length range for location data.
- valueRange specifies the range of valid values of a tag. For example, a person’s age could be between 0-125. If a column contains data beyond this range, K9 will skip this column for any “age” type check. Like lengthRange, valueRange also short-circuits a lot of complex matches.
- Pattern match specifies the regular expression to match with the typical pattern of a value. For example, emails always follow a pattern that we can use to check if a column value could be a potential email.
- columnNameMatch rule expresses the matching of column name pattern and column type. It could also mention the excluded column names and types that help to avoid false positives.
- ContextMatch rule looks for specific contexts that are beyond a particular column value. Currently, DataK9 supports two different contexts with respective matching scores:
- resourceContext specifies if there is any table or database name pattern that we want to get a signal. For example, if a database name contains “finance,” there is a high possibility of having transaction data in that dataset.
- categoryContext outlines what other associated categories could give additional signals. For example, a level 1 location data tag must have an identifiable personal category in the same dataset.
- DataK9 manages the rule’s definitions in one or more YAML files. Alternatively, DataK9 will support rules stored in a database table. The table would be better for dynamically updating the rules or the associated scores.
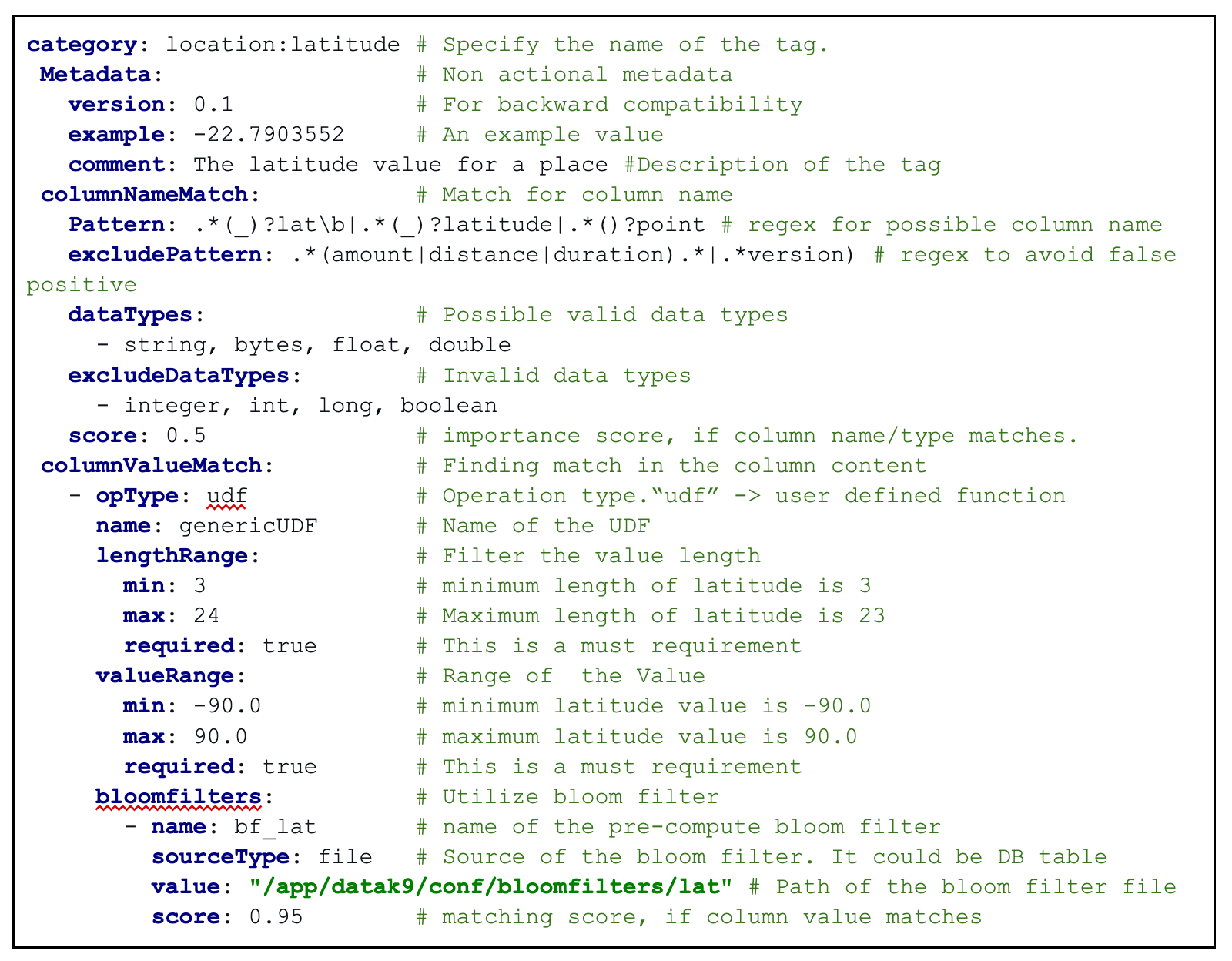
We present a set of sample rules for “location latitude” to identify a tag in YAML format in Figure 6, which will help understand the concept described in the earlier section. The inline comments in green color entail what each key-value pair means.
Learning-Based AI
Classification is very well studied in the AI/ML world. Our categorization problem fits well for supervised learning for multi-label classification. Using the standard classification algorithm, we intend to use both metadata and the cell content to predict the actual tag. The key idea is shown in Figure 7 and described below:
Figure 7: Learning-based AI
- Use labeled datasets to train our model. We can use metadata and the data values separately to train two models.
- Evaluate the trained model concerning typical accuracy, precision, recall, and F2 score metrics. If the value of the metrics is not acceptable, we retrain our model after adjusting the parameters and algorithm. Otherwise, we can deploy the model in production. Thresholding techniques may be employed to trade off precision and recall with greater control if the model scoring distributions are consistent. For categories with low support, the model may be improved by additional manual labeling. Combining categories may be considered in cases where additional manual labeling fails. ML models will be subjected to a full train/test experiment as a final sanity check before deployment. This experiment also has to pass established thresholds for all the above metrics. The DataK9 detector will predict the column’s tag-based on trained models.
- ML algorithms and initial experimentation: A sizable spectrum of ML algorithms have been put to the test, along with various input transformation and feature engineering strategies. We’ve checked out classic ML programs like Linear Support Vector Machine (SVM), K-Nearest Neighbors (KNN), and Naive Bayes. So far, the one that’s done the best is Linear SVM. However, there is still hard work ahead on ML modeling, especially when it comes to these low-support categories.
Aggregating Signals
As described above, DataK9 produces multiple signals with associated score values for each column. A column could have multiple potential tags along with scores estimated by the following methods:
- Rule-based AI creates tags and scores after applying rules for each category.
- Learning-based AI would predict possible pairs of tags and scores for each column based on metadata and column values.
- The lineage service could also provide additional signals for each column.
After collecting those signals, DataK9 combines all scores per tag, per column using a weighted aggregation method. The weights of each match are determined empirically and parameterized as part of the rule definition. The combined score determines the final tag after comparing it with pre-specified threshold values. Later versions of the product may use ML-based ensembling methods.
Learning: Feedback Loop
DataK9 heavily relies on ML/AI techniques that could make potential mistakes in label prediction. We intend to auto-learn to avoid similar mistakes by adopting a feedback loop. This section briefly describes how we fit this approach into our framework.
The first part of the challenge is identifying the mistakes. After the auto-tagging, the owner or privacy expert can modify the category using the provided UI. We will keep track of the audit trail of all these modifications in a central location. The next step is to find the typical mistake pattern that could auto-adjust the AI/ML platform. In particular, we strive to adapt our rule database, where we employ many parameters specified empirically. We plan to modify those parameters based on the patterns of mistakes. In addition, we want to alter the different model training parameters based on learning from errors. While our eventual goal is fully automatic, we will start with a human-in-the-loop to adjust the rules. We will eventually move towards an automated feedback loop based on our real-world understanding.
Measuring the Accuracy
In the realm of auto-categorization, accuracy reigns supreme, and thus, we’ve made it our priority to meticulously measure and disclose various levels of metrics tailored to our audience’s needs. At the pinnacle of our reporting hierarchy, we shall unveil the following key metrics:
Standard Metrics for Classification: The quality of our automation frameworks is critical to evaluating and tracking the progress. However, it is impossible to measure the quality of auto-categorization without a proper baseline. Hence, we also proposed that manual categorization of <1% of datasets covering all data tags by owners/experts would provide a realistic baseline. In the ML/AI world, classification is well-studied literature, and the experts defined a set of metrics to gauge the quality of a classification method. We show them in Figure 8 with a confusion matrix and describe them below:

- Accuracy: Classification accuracy is the total number of correct predictions divided by the number of predictions made on all datasets. In other words, this represents what percent of columns are appropriately tagged by machines for the labeled datasets. For instance, if we have 100 columns and K9 categories 90 of them correctly, the accuracy would be 90%. We cannot solely rely on accuracy, as columns with PII are a small percentage of all columns. A classifier that fails to classify anything would have an unusually high accuracy as the true negatives would outweigh the false negatives.
- Precision: Precision is how “correct” our positive predictions are. The fewer false positives, the better our precision. However, it does not tell the full story. For example, if we make a single prediction with a 100% success rate, but fail to categorize the other 9 sensitive columns, we have 100% precision, but low accuracy and low recall.
- Recall (sensitivity): Recall is how likely we are to identify sensitive information. The fewer false negatives, the better our recall. However, it does not tell the full story. For example, if we predict all columns are sensitive information, we will get 100% recall, but low accuracy and low precision.
- F2 Score: The F2 score is a way to skew towards optimizing recall over precision in a single measurable metric.
Precision vs. Recall
The impact of precision and recall would affect two different audiences. For example, low-precision metrics would be concerning for engineers and data scientists. Higher false positives would unnecessarily restrict access to non-sensitive data or delete them prematurely. If there are a lot of false negatives, the system might not be able to restrict sensitive data and enforce appropriate retention that would potentially violate the compliance contracts.
In addition to the above metrics, we strive to measure some additional metrics to track the engineering progress. These metrics measure the following perspectives:
- Automation quality: We want to measure how many auto-tags are overturned by humans such as data owners/admins.
- Scale: As we have to tag hundreds of thousands of datasets, we need to measure how many datasets we can onboard per day.
- Re-classification: When to re-classify any dataset based on schema changes or when new tags are introduced/updated.
- Efficiency: This initiative is based on data crawling, which is computationally expensive. We will track how much Uber pays to automate each data element (i.e., columns or tables).
- Operation Excellence: Once the development process and initial onboarding are over, we will track how much operations overhead is needed, such as support, bug fixing, and on-call.
- Storage System Coverage: As mentioned above, we have different storage technologies and backbones; tracking how many storage instances are onboarded to the categorization effort will be essential.
Production Experiences
Centralized Data Collection System
Uber employs a diverse range of storage systems across various infrastructures, each with its own unique characteristics. Some systems adhere to specific schemas, while others do not. Even among schema-based systems, there can be substantial variations in schema structures.
To streamline the categorization of data stored in these diverse systems, we have implemented a robust data collection system. This system samples data from different storage systems and consolidates them into a centralized data lake. Under this unified approach, the sampled data undergoes processing through a standardized workflow.
Key Benefits:
- Consistent Processing: By centralizing data into a common data lake, we facilitate the use of a standardized workflow for processing.
- Simplified Management: The approach simplifies the management of categorization jobs, offering a centralized point of control.
This strategy not only addresses the challenges posed by the varied nature of storage systems, but also enhances efficiency in data processing and management.
Advancements in Accuracy
Since its initial production launch, DataK9 has undergone continuous enhancements in accuracy over the past few years. We employ two key metrics to showcase the overall accuracy of DataK9 as illustrated in Figure 9:
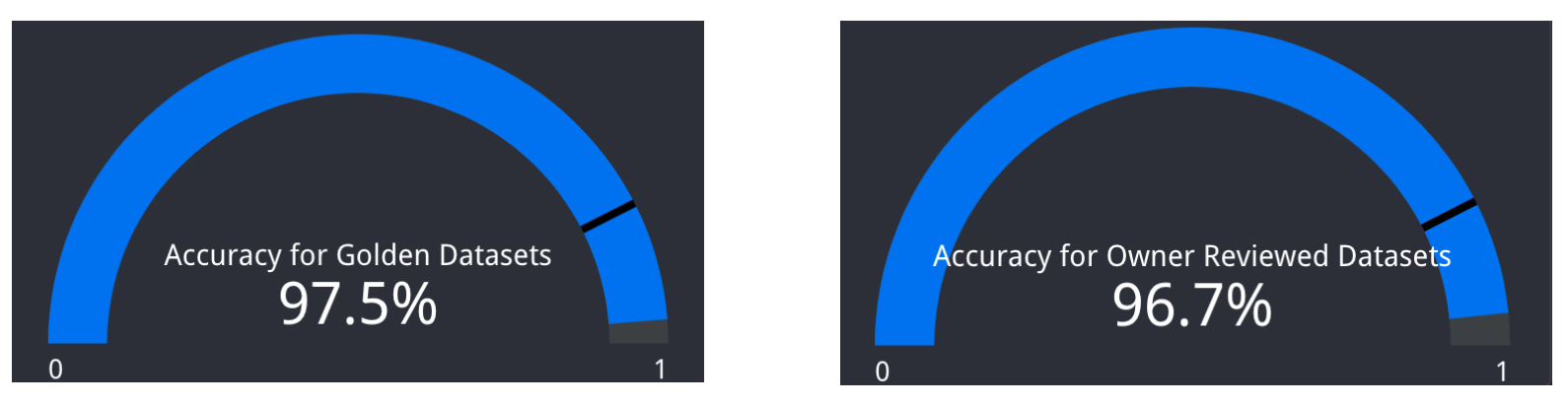
- Accuracy for Golden Datasets: In this approach, we compare tagging results with golden datasets meticulously reviewed by our internal privacy experts. This metric reflects the precision and reliability of DataK9 against a standard set by privacy experts.
- Accuracy for Owner Reviewed Datasets: Additionally, we evaluate accuracy by comparing results with the categorization performed by the data owners. This metric provides insights into the alignment of DataK9 with the intended categorization as defined by those responsible for the data.
These metrics serve as robust indicators, illustrating the continual commitment to improving accuracy and checking DataK9’s efficacy in meeting both internal privacy standards and the expectations of data owners.
Success Metrics & Funnel Analysis
In our pursuit of success, we have implemented a comprehensive set of metrics to gauge and optimize our automation process. A detailed funnel (see below) has been meticulously designed to facilitate the investigation and identification of gaps at each step. This invaluable tool provides a systematic approach to trace and monitor the overall categorization status, empowering us to make informed decisions and improvements.
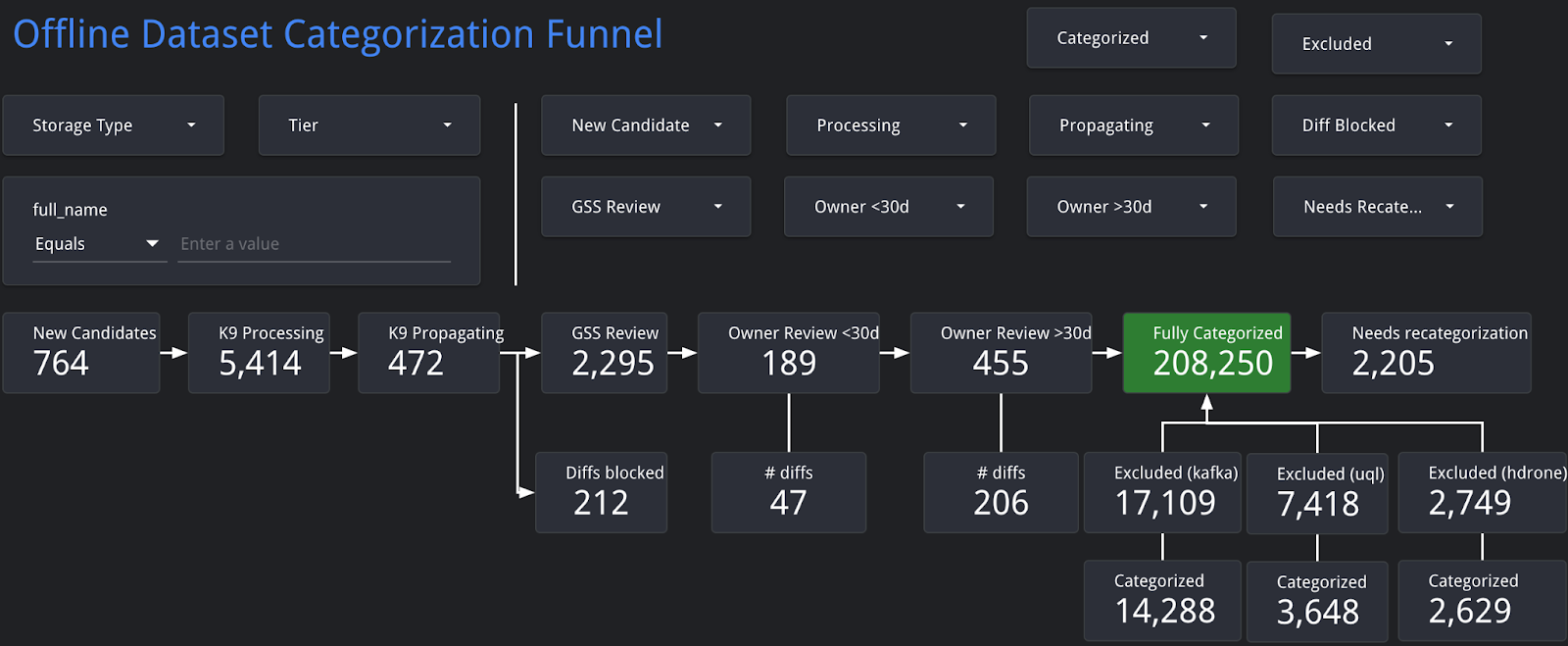
Key Benefits:
- Granular Analysis: The funnel allows us to dissect the automation process into individual steps, enabling a granular analysis of performance at each stage.
- Gap Identification: By employing the funnel, we can effectively identify and narrow down gaps in the automation process, streamlining our efforts to enhance efficiency.
- Traceability: The funnel serves as a reliable tracking mechanism, offering real-time insights into the categorization status and allowing us to trace progress over time.
This meticulous approach to success metrics and funnel analysis reinforces our commitment to continuous improvement and enables us to proactively address challenges within our automation process.
Conclusion
The DataK9 project at Uber represents a pioneering effort to address the challenges of categorizing data at scale and at the field level through the implementation of AI and ML technologies. Recognizing the fundamental role of data categorization for privacy and security initiatives, Uber has undertaken this initiative to automate and streamline the process.
Cover image attribution: “Categorization system 2” by MCruz (WMF) is licensed under CC BY-SA 4.0.
Apache®, Apache Hive, Hive, Apache Spark and Spark are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks.
[ad_2]
Source link

